

1. 서 론
2. 관련 연구 동향
3. 생성형 모델 기반의 데이터 증강 기법
3.1 스타일 전송을 위한 이미지 수집
3.2 가상 굴착기 이미지 및 자세 데이터 생성
3.3 CycleGAN을 이용한 스타일 전송
3.4 생성된 데이터세트의 성능평가
4. 결 과
4.1 포토리얼리즘 평가
4.2 컨텐츠 보존 능력 평가
5. 결 론
1. 서 론
확장 가능하면서도 최적화 가능한 기술과 막대한 양의 데이터를 처리할 수 있는 일련의 혁신이 정보 기술 분야에 도입됨에 따라 건설 분야에서도 기존 방법으로는 처리할 수 없었던 영상 등 새로운 유형의 데이터를 다룰 수 있는 딥러닝 및 컴퓨터 비전과 같은 인공지능 기술이 도입되고 있다. 특히, 다양한 유형의 데이터 수집이 용이해짐에 따라 건설 현장에서는 관리자의 지속적인 감독이 필요한 작업 등을 보조 ․ 대체할 수 있는 자동화 기술 및 인공지능 응용 모델들이 등장했다. 그 중 CCTV와 같은 영상 데이터를 활용하여 건설장비를 찾고 식별하는 등의 컴퓨터 비전 기반의 장비 모니터링 연구가 활발하게 이루어져왔다(Memarzadeh et al., 2013; Kim et al., 2018). 특히 최근에는 굴착기의 팔(arm)과 붐(boom)과 같이 시시각각 자세가 변화하는 장비로 인한 충돌 등의 안전사고를 예방하거나 장비의 생산성을 측정하기 위한 목적으로 장비의 자세를 모니터링하기 위한 시도 등이 이루어지고 있다(Tang et al., 2022).
건설장비의 자세 추정을 위한 딥러닝 기반의 컴퓨터 비전 기술은 장비 이미지 및 자세 레이블(label) 등의 학습 데이터를 수집하여 딥러닝 모델을 훈련시키고, 테스트 데이터를 통해 훈련된 모델을 평가하는 일련의 과정을 포함한다. 이 과정에서 막대한 양의 학습 데이터가 필요하지만, COCO(Common Objects in Context), CrowdPose(Efficient Crowded Scenes Pose Estimation and A New Benchmark), MPII(Max Planck Institute for Informatics) Human Pose dataset등 대규모로 구축, 공개되어 있는 인간의 자세 데이터세트와는 달리 건설 장비를 위한 벤치마크 데이터세트는 아직 구축되어 있지 않은 실정이다. 따라서 건설장비의 자세 데이터세트 확보를 위해서는 현장의 건설장비에 자세를 측정할 수 있는 센서(예, GPS)를 부착하거나 건설현장에 카메라를 설치하는 등의 노력이 요구된다. 하지만 이러한 작업은 장비의 주요 부위마다 센서를 부착하거나 현장에서 자세 데이터를 수집하기 위해 많은 시간이 소요되며, 파손되기 쉬운 현장 여건 상 새로운 센서를 계속 구입하여 설치하는데 상당한 비용이 소요된다(Luo et al., 2020). 이에 현장에서의 데이터 수집을 최소화하기 위한 방안으로 최근에는 실제 데이터(real-world data)에 대한 대체제로서 컴퓨터 시뮬레이션이나 알고리즘이 생성하는 합성데이터에 대한 연구가 활발히 이루어지고 있다. 하지만 기존 연구는 가상의 시뮬레이션 환경에서 생성한 데이터를 그대로 학습에 사용할 경우 현장에서 수집한 실제 이미지에 비해 포토리얼리즘(photorealism)이 떨어질 수 있는 한계를 가지고 있다.
이러한 학습 데이터 부족의 한계를 극복하기 위해 본 연구는 토공 작업에서 가장 많이 활용되는 장비이자 현장의 안전과 생산성을 위해 지속적인 감독이 필요한 굴착기를 대상으로 3차원 자세 데이터 추출이 가능한 가상 굴착기의 이미지에 실제 굴착기의 스타일 정보를 결합함으로써 굴착기의 자세 데이터 생성을 자동화하고자 한다. 본 논문은 이를 위한 선행 연구로서 비지도 학습 기법인 CycleGAN(cycle generative adversarial networks)을 활용하여 가상환경에서 생성된 이미지에 실제 굴착기 스타일을 전송하는 데이터 생성 방법을 제시한다. 이 과정에서 굴착기 이미지의 기하학적 변환(geometric translation)을 최소화하고자 자세 추정 모델을 목적함수에 반영하였으며, 생성된 이미지는 포토리얼리즘과 컨텐츠 보존 능력에 대한 평가를 통해 데이터 증강 모델로서의 활용 가능성을 살펴보고자 한다.
2. 관련 연구 동향
굴착기의 3차원 자세 데이터 수집을 위한 기존의 연구는 주로 현장에서 직접 데이터를 얻는 방식으로 행해졌다. 크게 센서 기반과 비전 기반의 연구로 나눌 수 있으며, 비전 기반의 연구는 다시 특정 지점의 탐지(detection)를 도와주는 마커 기반(marker-based)과 마커를 사용하지 않는 마커리스(marker-less) 기반의 연구로 구분할 수 있다. 이 중 센서 기반과 마커 기반의 기술은 현장의 객체(예, 굴착기 주요 부위)에 센서와 마커를 미리 부착해야 하기 때문에 역동적인 현장의 특성상 부서지거나 분실될 가능성이 높으며, 현장에서의 데이터 수집에 많은 시간과 노력을 요한다. 특히, 센서 기반의 방식은 주변 환경에 영향을 많이 받는 것으로 알려져 있는데, 예를 들어, IMU(inertial measurement unit) 센서는 주위 자기장의 영향을 많이 받기 때문에 건설 현장에서 데이터 분실의 위험이 있고, GPS는 밀집된 공간에서 사용시 신호장애가 발생할 수 있다. 반면 마커리스(marker-less) 기반의 접근법은 깊이 및 RGB 센서를 장착한 RGB-D 카메라가 보급되면서 최근 건설 분야에서도 많이 사용되고 있다(Liang et al., 2019). 하지만 3D 자세 데이터 수집을 위해 여러 시점에 고정된 카메라를 설치해야 하기 때문에 동적인 현장의 특성상 설치 및 관리가 힘들다. 또한 structure-from-motion과 같은 3차원 복원 기술의 경우 다수의 이미지 쌍으로부터 삼각측량하여 추가적인 깊이 정보를 생성하기 때문에 계산 과정이 길고 복잡하며 동적인 이미지를 다루는 데는 한계가 있다.
이러한 현장 데이터 수집의 어려움을 해소하기 위한 방안으로 최근에는 동영상 스트리밍 서비스와 디지털 플랫폼을 활용하여 직접 현장에 가지 않고도 데이터를 수집할 수 있는 접근법이 제안되었다. 대표적으로 현장 영상으로부터 데이터를 추출하고 주석화하는 연구와 합성데이터를 생성하는 연구가 행해지고 있다. 전자의 경우 다수의 평가자가 자율적으로 참여하는 방식인 크리우드소싱(crowdsourcing)을 기반으로 한 연구가 이루어지고 있는데, 예를 들어, Liu and Golparvar-Fard (2015)는 크라우드소싱을 기반으로 현장 영상에서 작업을 분석하는 연구를 진행했고, Wang et al.(2019)은 현장 영상을 활용하여 안전 규칙을 위반한 프레임이 포함된 이미지 데이터세트를 구축하는데 크라우드소싱 접근법을 제시했다. 크라우드소싱은 처리하기 어려운 대규모 문제를 해결할 수 있다는 장점이 있지만, 평가자의 육안에 의존하여 학습 데이터를 생성할 경우 평가자의 주관성과 사전지식이 결과에 영향을 미칠 수 있는 한계가 있다.
이에 최근에는 가상의 시뮬레이션 환경에서 합성데이터의 생성을 통해 데이터세트를 구축하는 연구가 활발히 이루어지고 있다. 게임 엔진을 활용하여 굴착기 2D 자세 추정을 위해 주석이 달린 데이터세트를 생성하는 방법이 고안되었으며(Assadzadeh et al., 2022), 이러한 방식으로 생성된 데이터를 활용하여 굴착기의 3D 자세를 추정하거나(Mahmood et al., 2022) 굴착기의 작업을 인식하는 연구(Torres Calderon et al., 2021)도 진행되었다. 또한, 작업자를 대상으로 학습데이터로 사용된 합성이미지가 딥러닝 기반의 객체 탐지 모델의 성능에 미치는 영향에 대한 조사가 이루어지기도 하였다(Kim et al., 2023). 하지만 기존 연구에서는 합성이미지와 실제 현장 이미지와의 시각적 간극을 줄이기 위해 해당 객체(예, 굴착기, 작업자)의 합성이미지를 실제 이미지의 배경에 중첩시키거나 이미지 배경에 임의로 노이지를 추가하는 등 객체 탐지 및 자세 추정을 위한 딥러닝 모델의 성능을 실제 이미지로 학습할 때와 유사하게 유지시키기 위한 노력들이 추가적으로 이루어졌다. 이에 본 논문에서는 생성형 모델을 활용하여 가상 공간에서 촬영된 굴착기에 현장 영상에서 추출한 굴착기의 스타일을 입혀 실제와 유사한 이미지를 생성할 수 있는 모델을 제안하고자 한다.
3. 생성형 모델 기반의 데이터 증강 기법
컴퓨터 비전 기반의 굴착기 자세 추정 알고리즘을 학습하기 위해서는 굴착기의 이미지와 굴착기 주요 부위(예, 붐, 버킷)의 3차원 위치 데이터가 필요하다. 이를 위해 가상 환경에서 다양한 굴착기의 자세를 생성하고 주요 부위의 3차원 위치 데이터(예, x, y, z 좌표)를 추출할 수 있는 게임 엔진(Unity)을 활용할 수 있으며, 자세 데이터와 함께 다양한 각도 및 거리에서 굴착기의 이미지를 추출함으로써 자세와 이미지 쌍으로 구성된 학습 데이터를 생성하는 것이 가능하다. 본 논문은 이러한 데이터 증강 절차 중 다양한 각도에서 굴착기 모델의 이미지를 추출하고, 다시 실제 굴착기와 유사한 이미지로 변환하는 과정을 연구 범위로 한다. 제안된 굴착기의 자세 데이터 증강을 위해서는 가상 굴착기 이미지세트 및 자세 정보와 스타일 전송을 위한 이미지세트가 구축되어야 한다. 실제 굴착기 이미지는 현장 영상에서 추출하였고, 가상 굴착기 이미지 생성을 위해 시뮬레이션 환경에 굴착기 모델을 생성하여 다양한 자세의 가상 굴착기를 촬영하였다. 스타일 정보를 전송하기 위해 비지도 생성형 모델인 CycleGAN을 사용하였으며, 이미지 변환 시 굴착기 자세를 보존하기 위해 자세 추정 모델을 목적함수에 반영하였다. 이러한 생성형 모델은 이미지는 콘텐츠와 스타일의 고유한 조합이라는 개념에 착안하여 실제 이미지에서 특정 스타일만을 추출하고 이를 다른 가상의 컨텐츠와 결합하여 실제 이미지처럼 보이는 새로운 이미지를 생성하는 기법(Liu et al., 2019)으로, 가상 굴착기 이미지로부터 생성된 이미지의 포토리얼리즘을 향상시킬 수 있을 것으로 기대된다. 성능 평가를 위한 실험을 통해 생성형 모델(CycleGAN)을 활용하여 가상 이미지로부터 실제와 유사한 이미지를 생성할 수 있는지, 그러한 생성 이미지가 분류 모델과 같은 기계학습 기법으로 구분이 가능한지를 평가하며, 이는 생성된 데이터의 포토리얼리즘과 컨텐츠 보존 능력을 측정함으로써 검증하였다.
3.1 스타일 전송을 위한 이미지 수집
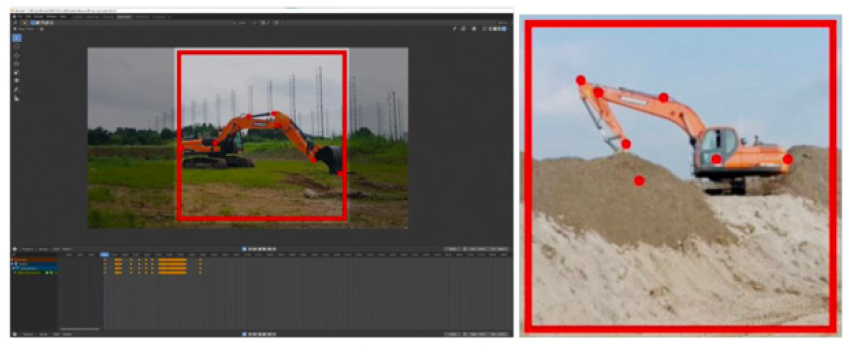
게임엔진에서 생성된 가상 굴착기 이미지에 실제 굴착기의 스타일을 전송하기 위한 이미지세트는 현장의 실체 굴착기를 촬영한 영상으로부터 프레임을 추출하여 구축하였다. 추출한 이미지는 자세에 대한 정보를 포함하고 있지 않아 3D 그래픽 툴인 Blender의 자세 마커(pose marker)기능을 활용하여 2차원 자세를 주석화(labeling)하였다(Fig. 1). 또한 스타일 전송 시 불필요한 요소로부터 간섭을 최소화하고자 굴착기 이외의 다른 장비가 등장하지 않도록 이미지를 자르고 정렬했다.
3.2 가상 굴착기 이미지 및 자세 데이터 생성
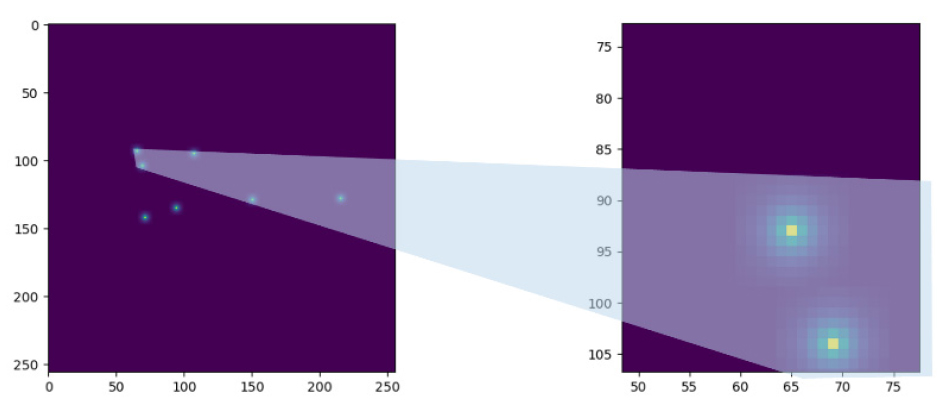
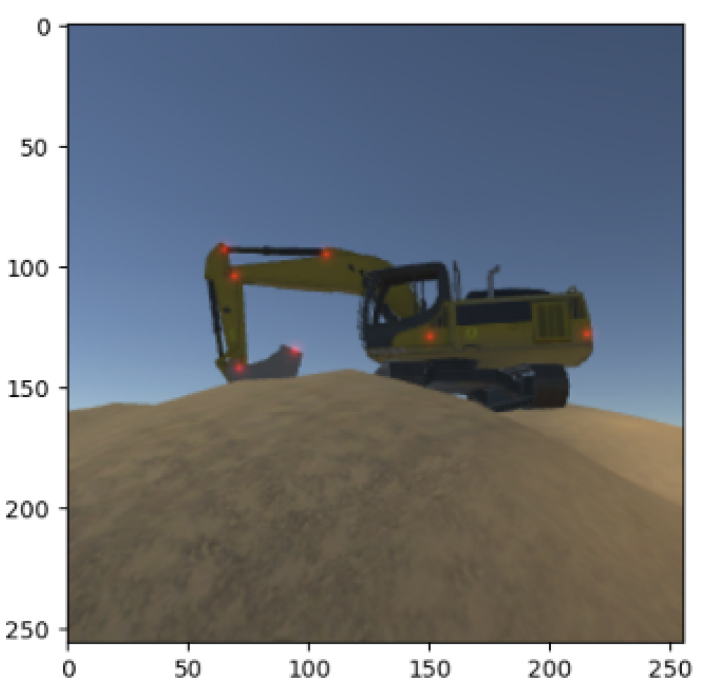
가상 굴착기 이미지세트와 그에 상응하는 자세 데이터 생성을 위해 3D 게임 제작 툴인 Unity로 가상 환경을 구축하여 굴착기의 물리적 움직임을 시뮬레이션하고, 2차원 가우스형 히트맵(two-dimensional Gaussian-like heatmap)을 설계하여 자세 레이블을 생성하였다(Fig. 2). 스타일 전송 및 이미지 생성 시 왜곡이 일어나지 않도록 굴착기 영상과 유사하게 가상 굴착기와 카메라를 배치하였다. 가우스 히트맵 레이블은 화면 포인트 레이블을 더 시각화(Fig. 3) 시킬 뿐만 아니라 정확도를 평가하기 위한 정량적 손실을 계산하는데 활용될 수 있다.
3.3 CycleGAN을 이용한 스타일 전송
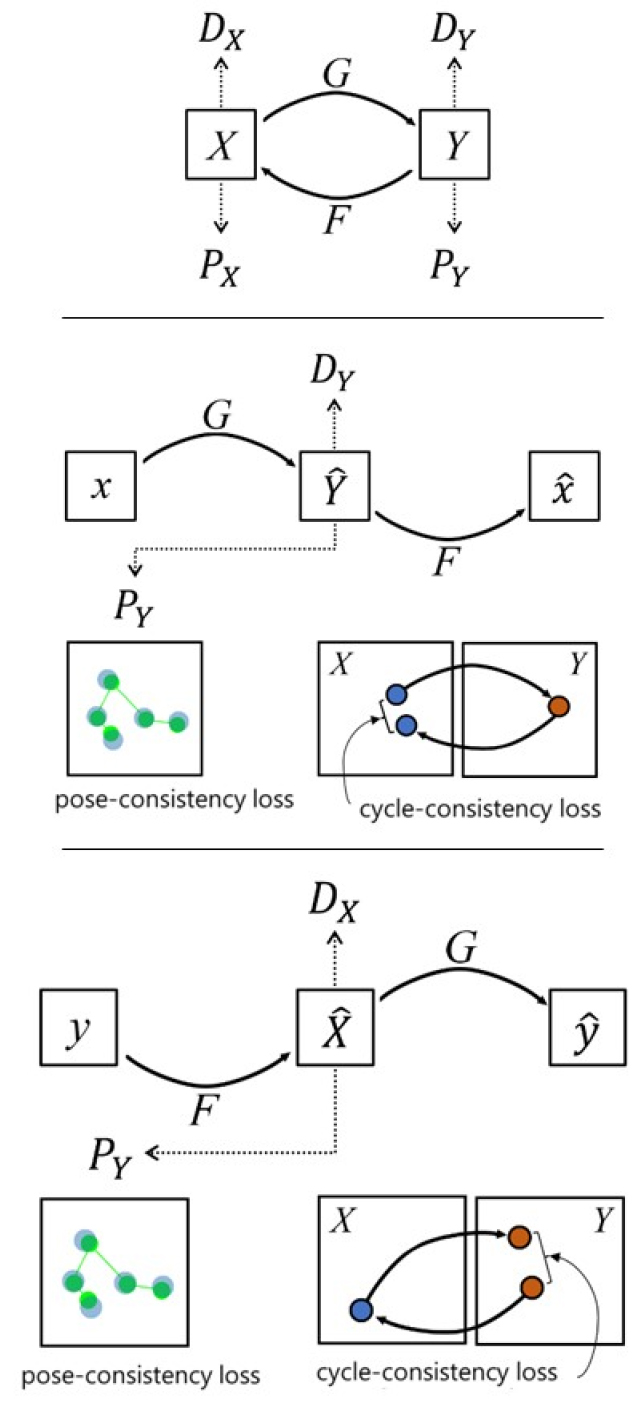
가상 굴착기 이미지에 실제 굴착기 스타일을 전송하여 실제 굴착기처럼 보이게 하기 위해 생성형 모델인 CycleGAN을 사용하였다. 생성적 적대 신경망(GAN, generative adversarial networks)은 진짜와 같은 가짜 데이터(예, 이미지)를 만드는 생성자(generator)와 생성된 데이터가 진짜와 가짜 데이터 중 어디에 속하는지를 결정하는 판별자(discriminator)가 서로 경쟁하면서 가짜 데이트를 최대한 진짜와 비슷하게 만들기 위해 생성자와 판별자를 학습시킨다. 본 논문에서 적용한CycleGAN은 위 과정에서 생성된 데이터를 다시 원래의 데이터(input)로 변환 가능하도록 하기 위해 일관성 손실 함수(cycle consistency loss)를 사용함으로써 기존의 GAN 모델과 달리 변환하려는 이미지의 쌍(pair)이 필요하지 않고, 비슷한 이미지만 계속 생성해내는 모드 붕괴(mode collapse) 현상을 해결하는데 효과적이다. 또한 일관성 손실 함수는 스타일 전송 후 변화된 이미지로부터 입력 데이터를 복원한 이미지와 원래 입력 데이터를 비교하는 것으로 손실을 산출함으로써 왜곡 없는 이미지 생성을 가능하게 한다. 본 논문에서는 추가적으로 자세 일관성 손실(pose consistency loss)을 목적함수에 반영하여 굴착기의 위치와 방향 정보를 보존하였다. 이는 자세 추정 모델로서 전송 사이클 중간에 위치하여 각각의 사이클 단계에서 생성된 이미지가 기하학적 정보를 잘 보존하고 있는지 평가한다(Fig. 4).
3.4 생성된 데이터세트의 성능평가
생성된 이미지가 실제 굴착기 이미지와 비슷한 수준의 품질을 제공하며 정확한 자세를 취하고 있는지 평가하기 위해 포토리얼리즘과 컨텐츠 보존 능력을 평가하였다.
포토리얼리즘은 Salimans et al.(2016)가 제안한 IS(inception score)의 정량적 평가 방법론에서 범용 이미지 분류 모델을 활용하는 아이디어를 차용해 생성된 이미지를 적절한 클래스로 분류해 내는지를 정량적으로 확인함으로써 제안 기술로 생성한 데이터가 딥러닝 모델의 학습데이터로써의 적용 가능한지를 간접적으로 평가하였다. 이미지 분류 모델의 학습용 데이터세트는 스탠포드 대학에서 만든 Tiny ImageNet을 사용하였으며, Tiny ImageNet의 200가지 클래스 중 기계, 장비, 차량에 가까운 5개의 클래스에 대해 각각 100개의 샘플을 임의로 추출하고 가상 굴착기 이미지 샘플 100개와 제안 기술로 생성된 샘플 이미지 100개를 각각의 데이터세트(총 600개의 샘플 중 학습과 평가 데이터 비율은 75%와 25%)로 구축하여 웹기반의 머신러닝 모델인 Teachable Machine으로 데이터를 학습시켰다. 가상 및 생성 이미지로 각각의 모델을 학습한 이후에는 실제 이미지세트에 대해 분류 모델이 이들을 적절한 클래스로 분류하는지를 검정하였으며, 분류 성능 평가에 흔히 사용하는 정확도(accuracy, Eq. 1)와 F1-Score(Eq. 2)를 측정하여 두 그룹 간의 차이를 비교하였다. 예를 들어, F1-Score는 정밀도(precision)와 재현율(recall rate)의 조화 평균으로 데이터의 편향을 확인하는 지표로서 F1-Score가 1에 가까울수록 분류 성능이 높은 모델을 의미한다.
컨텐츠 보존 능력은 가상 굴착기 이미지와 생성 이미지를 육안으로 비교하여 굴착기 자세와 실제 굴착기의 스타일을 얼마나 잘 복제하였는지 평가하였다.
4. 결 과
4.1 포토리얼리즘 평가
포토리얼리즘 평가를 위해 Tiny ImageNet의 데이터세트로 객체 분류 모델을 훈련하였다. Fig. 5은 학습 과정의 정확도(accuracy) 및 오차(loss)의 변화를 보여준다. 학습 횟수를 의미하는 에포크(epoch)를 늘릴수록 정확도는 높아지고 오차가 낮아지는 것으로 보아 학습이 잘 진행되었음을 알 수 있다.
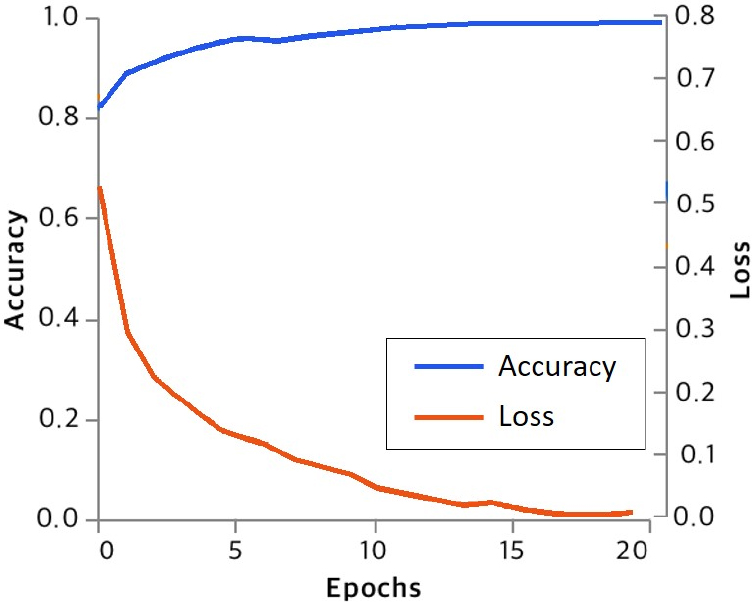
분류 모델을 가상 굴착기 이미지(Unity simulation)와 생성 이미지로 각각 학습시켜 비교한 결과(Table 1) 가상 굴착기의 이미지만 사용하여 학습을 시킨 분류 모델을 실제 이미지에 적용했을 때 과적합(overfitting) 등으로 인해 불안정하고 부정확한 결과를 보이는 반면, 생성 이미지로 학습시켰을 때는 월등히 높은 분류 정확도를 얻었음을 확인할 수 있었다. 이는 생성 이미지가 실제 이미지와 보다 유사하다는 것을 의미하며, 그러한 포토리얼리즘이 실제 분류 정확도에 큰 영향을 미쳤음을 나타낸다. 특히, 이 결과는 이미지 객체 분류 모델의 경우 객체를 인식함에 있어 이미지가 가지는 스타일 정보가 객체의 크기, 형상과 같은 정보와 함께 매우 큰 영향을 미칠 수 있음을 시사한다. 또한 이전 연구(예, Kim et al., 2023)에서 학습 데이터 구축 시 가상 이미지와 실제 이미지를 합성하거나 함께 사용한 것과 같이 가상 이미지만으로 학습한 분류 모델을 실제 이미지에 적용할 때 분류가 제대로 되지 않을 수 있음을 의미한다. 따라서, 본 연구결과는 굴착기 자세 예측을 위한 데이터세트로서 합성데이터의 활용가능성을 보여준다.
Table 1.
Performance comparison between generated and virtual images by epoch (accuracy with F1-score in parentheses)
| Dataset | 10 Epoch | 20 Epoch | 30 Epoch |
|
Generated image |
99.97% (1.00) |
99.89% (0.99) |
99.20% (1.00) |
|
Virtual image (Unity) |
6.42% (0.12) |
54.10% (0.70) |
22.31% (0.36) |
4.2 컨텐츠 보존 능력 평가
컨텐츠 보존 능력은 가상 굴착기 이미지와 생성 이미지를 비교함으로써 시각적으로 검증하였다(Fig. 6). 자세 추정 모델이 보조 판별자로 적용되어 원본 이미지의 컨텐츠 정보를 보존하게 함으로써 자세가 보존되는 효과를 확인할 수 있다.

그러나 이미지 생성 과정에서 카메라 위치에 대한 정보를 전달하지 않아 굴착기가 상방 이동이 발생하는 것을 확인할 수 있다(Fig. 7). 이는 영상 촬영 시 카메라가 굴착기를 정면으로 보지 않았고, 굴착기 이외의 장비가 프레임에 들어오지 않게 하기 위해 프레임을 자르면서 현장 영상의 프레임에서 굴착기의 위치가 중심보다 약간 위 쪽에 위치했기 때문으로 판단된다. 이러한 오차의 방향과 크기는 대부분의 이미지에서 일관되게 발생한 것으로 보아 다양한 각도 및 거리에서 촬영한 실제 굴착기 이미지를 사용할 경우 오차를 줄일 수 있을 것이라 판단된다.

5. 결 론
본 연구는 시뮬레이션 환경에서 자세 데이터를 포함하는 가상 굴착기 데이터를 생성하고, CycleGAN 기반 생성 모델을 사용하여 가상 굴착기 이미지를 실제 굴착기 스타일로 변환하는 데이터 생성 방법을 제안한다. 생성된 이미지의 포토리얼리즘과 컨텐츠 보존 능력을 평가함으로써 원본 이미지 재현 성능을 확인하였으며, 실제 이미지로 학습을 시킨 것과 유사하게 매우 높은 분류 정확도를 달성하는 것을 확인하였다. 이는 생성된 합성데이터가 굴착기 자세 추정 데이터로 활용이 가능함을 잠재적으로 의미한다.
최근에는 딥러닝과 컴퓨터 비전을 기반으로 한 연구가 건설 분야에서 활발히 이루어지고 있다. 이러한 방법을 적용하기 위해서는 막대한 양의 현장 데이터가 필요하며, 이에 이미지 생성 모델에 대한 연구가 지속적으로 이루어지고 있다. 향후 자세 보전 성능의 고도화 및 자세 추정 정확도 등 정량적 평가에 대한 추가적인 연구가 필요하며, 이를 통해 본 연구에서 제안하는 데이터 증강 기법이 건설 현장에서 얻기 어려운 데이터를 보다 손쉽게 취득하는데 활용될 수 있을 것으로 기대된다.
