

1. 서 론
1.1 연구 배경
1.2 연구의 취지
1.3 문제 도출
2. Miniature-Scale Radio-Controlled Excavator Robot
3. 사전검증 결과 및 결론
1. 서 론
1.1 연구 배경
건설산업은 인간사회 및 도시경제 발전에 큰 역할을 담당하고 있다. 전 세계적인 규모로 보았을 때, 글로벌 건설산업은 매년 $10조(USD) 규모의 상품과 서비스를 제공하고 있으며, 건설부문 고용인원은 약 1억 인구에 달한다 – 이는 전세계 GDP 및 고용인원의 약 13% 그리고 8%에 달하는 수치이다(McKinsey Global Institute, 2017; International Labour Organization, 2019).
빠르게 증가하는 세계 인구와 급격한 도시화를 고려하였을때, 건설산업의 역할과 그 비중은 앞으로도 더욱 커질 전망이다. United Nation(UN)의 한 조사에 따르면, 2050년 세계 인구는 97억명에 달할 것으로 예측 되었으며, 그 중 도심지 인구 비중은 전체 대비 70%에 달할 것으로 예측된다(United Nation, 2019). 이에, 2040년까지, 전 세계에서, 약 $97조(USD) 규모에 달하는 도시기반 시설 수요가 있을 것으로 예상되고 있다(Global Infrastructure Outlook, 2022).
허나, 기존 건설산업의 생산성 및 공급력이 수요를 충족시킬 수 있는가에 대해선, 부정적인 견해가 상당하다. 침체된 생산성, 높은 사망/사고율, 젊은 숙련공의 부족 및 높은 이직률, 낮은 수익률 및 높은 파산율등의 꾸준한 통계치들은, 그 부정적인 견해들을 잘 뒷받침 한다.
국가적 차원에서의 수요-공급 문제 뿐만 아니라, 실제 건설사들이 겪고 있는 위 문제들, 그리고 인부의 취약한 안전 및 건강(e.g., work-related muscular skeletal disorder) 문제들까지 고려해보았을 때, digital transformation으로 거론되는 Industry 4.0 레벨로의 기술혁신은 필요가 아닌, 필수라 보여진다.
1.2 연구의 취지
시각적 인공지능(visual artificial intelligence)은 RGB, RGB- D, RGB-IR 등의 영상정보(imagery data)를 입력값으로, 이미지분류(image classification), 물체검출(object detection), 의미론적 분할(semantic segmentation), 3D 스캐닝(3D reconstruction) 등의 시각적 장면이해(visual scene understanding)를 수행하는 computational models을 일컫는다. Visual AI는 건설로봇, 디지털트윈 등 영상분석을 필수로하는 Industry 4.0의 핵심 기술이다. 본 고를 통해 저자는 건설 분야 Visual AI 개발 연구들이 겪고 있는 학습데이터 측면에서의 과제들을 짚어보고, 이에 대한 하나의 접근 방법으로서 miniature-scale radio-controlled(RC) equipment의 사용방안에 대해 소개하고자 한다.
1.3 문제 도출
Deep neural network(DNN)로 구성되는 Visual AI 모델들은 학습하는데 있어, supervised learning에 그 기반을 둔다. 자연스럽게도 따라서, Visual AI 모델들의 성능은 학습시에 사용되었던 학습데이터(training data)의 양(quantity), 질(quality), 그리고 다양성(diversity)에 크게 영향을 받게된다. 그 어떤 경우에서라도(e.g., even if high quality training images with diverse contexts are given) 데이터의 양이 충분하지 않다면, supervised learning의 특성상 model complexity와 data quantity 사이에서의 불균형으로 인해 무조건 overfitting이 발생하게 된다. 이와 마찬가지로, 데이터의 양이 충분하다고 해도 scene context에 대한 다양성(diversity)이 부족하다면, overfitting은 주어진 결과라 할 수 있다. DNN 학습은 주어진 문제에 대해 답을 찾아가는 과정에서 imaging condition과 scene context에 invariant한 공통의 특징점은 무엇인지 해명하는 과정이다. 따라서, highly reliable common features를 규명해내기 위해선 그만큼 많고 다양한 예제들에 대한 학습이 필요 한 것이다.
Construction robotics 그리고 digital twinning에 대하여 DNN-powered visual AI 모델은 필수적이며, 여전히 많은 연구개발 과제가 남아있다. 하지만, 많은 연구들이 여전히 quantity, quality, and diversity를 모두 충족하는 학습데이터를 구축하는데 어려움을 겪고 있다. 현장 방문, 데이터 수집, 매뉴얼 레이블링 등의 일련의 과정은 굉장히 많은 시간과 투자를 필요로 한다. 특정 레이블링의 경우 추가 measurement tool없이는 불가능하며, 많은 경우 실 현장에서의 데이터수집이 불가능한 사례 또한 많다. 예를 들어, excavator의 3D joint locations을 레이블링 한다고 할때, Inertial Measurement Units(IMU) 또는 ViCON과 같은 추가 장비를 사용해야 하지만, 실 현장에서 activated mobile excavator를 대상으로 해당 측량장비를 적용하여 데이터를 수집한다는 것은 사실상 불가능에 가깝다. 따라서, 건설부문, 개별 연구들에서 가용한 학습데이터의 양들이 매우 한정적인 경우가 많고, 이로 인해 연구가 지연되는 경우 또한 많다.
컴퓨터비전 학계에서 사용되는 benchmark 학습데이터(e.g., ImageNet, H3.6M, or COCO)의 양에 견주어 보았을때, 건설연구에서 사용되는, 건설현장을 배경으로하는, 학습데이터의 양은 약 10% 미만인 경우(혹은, 그보다 더 적은 경우)가 대부분이다(Xiao et al., 2021). 학습데이터가 부족한 경우, 사용중인 DNN architecture에 대한 maximum performance potential을 확인할 수 없다(Delgado et al., 2021). 뿐만 아니라, deeper network에 대한 사용을 고려할 기회 조차 잃게 된다(Akinosho et al., 2020). 이는 분명 더 심한 overfitting을 야기하게 될 것이기 때문이다. 연구팀들 사이에서 공유되는 benchmark 학습데이터의 부재 또한 문제이다. Benchmark 학습데이터의 부제로 인해, 즉, 각 연구들 마다 각자의 학습데이터를 사용하기 때문에, 학계 내에서, DNN architecture와 hyper-parameter에 대한 comparative benchmarking이 이루어 지고 있지 못하고 있다.
2. Miniature-Scale Radio-Controlled Excavator Robot
본 연구에서는 건설장비 대상, 장비의 3D and 2D poses를 자동적으로 레이블링 할 수 있는 방법으로서 miniature-scale radio-controlled(RC) equipment의 사용 방안을 제안하고자 하며, 본 단계에서는 실 현장에서 많은 비중을 차지하고 있는 excavator를 대상으로 연구를 수행하였다(Fig. 1).
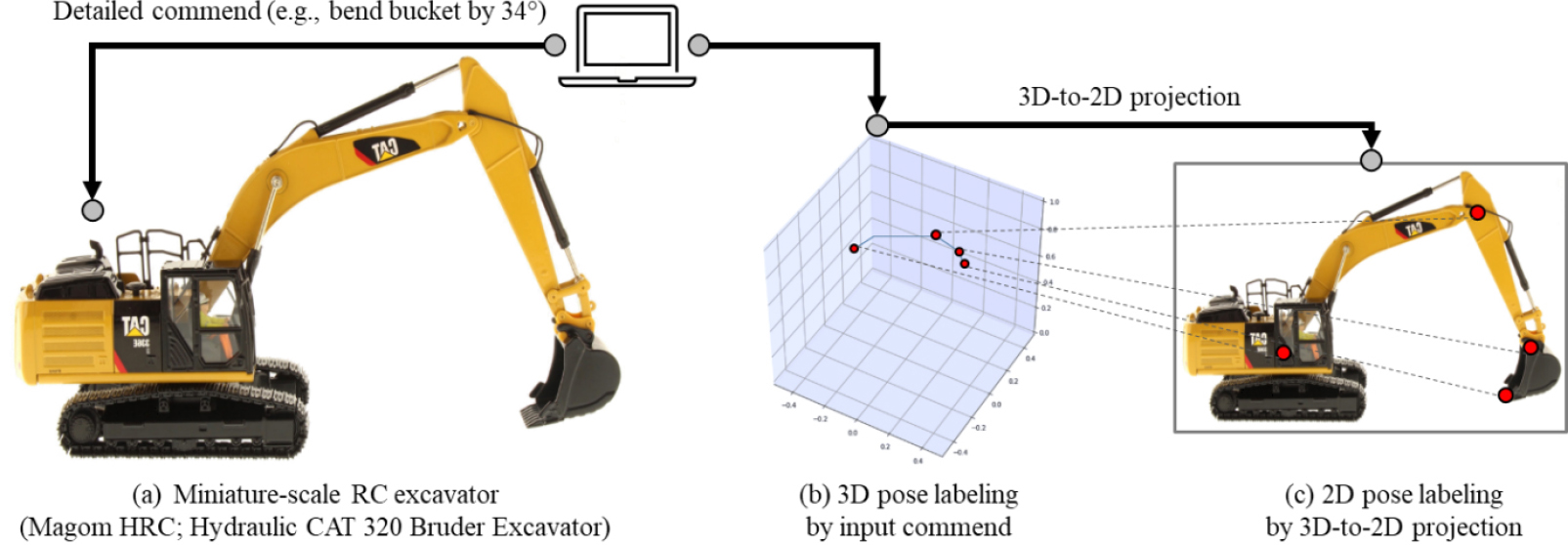
Monocular camera-based 2D and 3D excavator pose estimation을 위한 Visual AI를 학습시키기 위해선 3 종류의 데이터가 필요하다: 첫째, 2D image; 둘째, 2D skeleton on the 2D camera coordinate system; 그리고 셋째, 3D skeleton on the 3D camera coordinate system(i.e., z-axis added). 본 데이터들을 실제 현장에서 수집/레이블링 하기란 쉽지 않다. 또한 3D skeleton의 경우 실측을 위한 추가적인 tool 사용이 불가피하며, 이에 발상하는 추가적인 오차까지 감수해야 한다. 실측한 값(e.g., 3D joint locations)들을 과연 ground truth로 인정할 수 있을지도 의문이며, 무엇보다도 실측하여 방대한 양의 데이터를 확보하는 것 자체가 불가능하다.
Miniature-scale RC excavator를 활용한다면, 본 문제를 우회할 수 있다. 3차원의 시각정보를 2차원의 이미지화면에 맵핑하는 과정에서 깊이 정보, 즉 스케일감이 사라지게 된다. 우리는 이 과정을 역이용 할 수 있다. 예를 들어, 실제 크기의 excavator를 10m앞에서 촬영한 경우, miniature-scale excavator를 1m앞에 촬영함으로써 비슷한 결과를 얻어 낼 수 있는 것이다(Fig. 1(a)). 여기서, 만약 user 가 excavator의 motion에 대한 보다 명확한 commend를 전달 할 수 있고(e.g., bend bucket angle by 60 degrees), 이를 정확하게 miniature-scale RC excavator가 수행해 낸다면, 해당 commend로 부터 ground truth 3D skeleton을 reconstruct 할 수 있다(Fig. 1(b)). 나아가, the reconstructed 3D skeleton을 기 설정된 camera’s virtual plane에 영사시킴으로써, 수집된 이미지와 상응하는 2D skeleton 까지 자동적으로 레이블링 할 수 있게 된다(Fig. 1(c)).
본 연구는 off the shelf miniature-scale RC excavator(i.e., Vendor=Magom HRC; Model=Hydraulic CAT 320 Bruder Excavator)을 baseline으로 시작하였다(Fig. 2(a)). 본 모델은 mechanical parts, connections, and standard structure 측면에서 real-scale excavator와 동일하며(Fig. 2(a)), 외장소재 역시 metallic 소재로 마감되어 이미지내에서 실제 excavator와 같은 효과를 보여준다. 본 모델은 equipment-controller connection을 기본으로 하며, controller를 통해 equipment에 명령을 하달하는 방식이다. 기존의 RC 시스템은 transmitter(i.e., Radiolink AT9S Pro 2.4GHz), receiver(R12DS), 그리고 motor (pump and servo)로 구성되어 있다(Fig. 2(a)). 우리는 본 모델의 RC 시스템을 Bluetooth module(i.e., HC-05) and Arduino (i.e., Arduino Mega 2560)를 통해 변경하여(Fig. 2(b)), 기존의 equipment-controller connection이 아닌 equipment-laptop connection이 가능토록 하였으며, 이를 통해 보다 정확한 명령을 전달 및 수행 할 수 있도록 하였다(e.g., bend bucket by 30,31,32,33,34, or 35 degrees; rotate body by 184 degrees).

3. 사전검증 결과 및 결론
Miniature-scale RC excavator 시스템을 통해 얻을 수 있는 3D excavator pose에 대한 사전 정확도 검증을 수행하였다(Fig. 3). 본 단계에서는 bucket angle의 정확성 검증에 초점을 두었다. Laptop을 통해 특정 bucket angle 값을 갖도록 명령, 그리고 곧바로, 실측을 통해 시스템의 estimate(명령값)과 measurement(실측값)을 비교하였다. 실측에는 보다 정확한 실측을 위해 digital protractor를 사용하였으며, bucket angle range인 30°–184° 사이에서 균일하게 총 150회 실측비교 하였다.
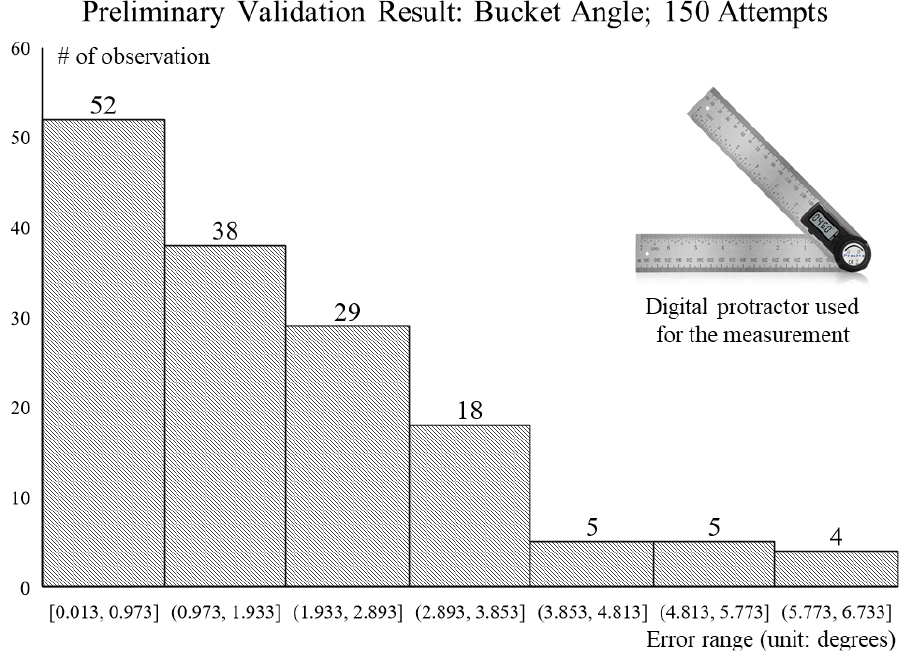
검증 결과, bucket control에 대하여 높은 수준의 정확성을 확보할 수 있었다. 평균적으로 1.86° mean absolute difference (MAD)를 달성하였다: 총 150회의 실측검증 중에서 총 52회에 한하여 1° 미만의 오차를 기록하였으며, 3.8° 이상의 오차를 기록한 경우는 단 14회에 불가했다. MAD 최저치는 0.013°를 기록하였으며, 최대치는 6.733°로 확인되었다(Fig. 3).
본 연구팀은 향후, main arm, middle arm, body rotation, and left and right track의 motion에 대한 검증을 이어갈 것이다. 본 검증을 통해, 제안하는 시스템의 3D pose labeling의 정확성 및 반복성을 통계적으로 입증하고자 하며, 이어서, (1) 3D-to-2D project을 통한 2D labeling 자동화; (2) miniature- scale image-based DNN training 실험을 이어갈 계획이다.
