

1. 서 론
1.1 연구의 배경 및 목적
2. 관련 연구
2.1 시소러스(Thesaurus)
2.2 Natural Language Processing
3. 시소러스 개발 과정
3.1 데이터 수집 및 전처리
3.2 시소러스 구축
4. 결과 및 고찰
4.1 시소러스 자동 구축 결과
4.2 시소러스 시각화
4.3 시소러스 활용 방안
5. 결 론
1. 서 론
1.1 연구의 배경 및 목적
1.1.1 연구의 배경
건설산업은 본질적으로 경험적인 산업으로, 현장에서 발생하는 다양한 문서들은 경험지식을 포함하고 있다(Al Qady and Kandil, 2013; Moon et al., 2018). 자연어처리(Natural Language Processing; NLP)와 텍스트마이닝(Text Mining; TM) 기술로 문서 데이터를 분석하면, 이러한 경험지식을 확보하여 유용한 정보를 추출할 수 있다(Zhang and El-Gohary, 2016; Zhang and El-Gohary, 2021; Wu et al., 2022). 그러나 기존의 자연어처리 기술은 건설산업에 특화된 용어와 표현을 이해하는 데 한계를 보인다.
대규모 언어 모델(Large Language Mode; LLM)의 등장으로 텍스트마이닝 분야에서 뛰어난 성능을 보이고 있으나, 여전히 건설산업에 특화된 용어 및 표현을 이해하는 데는 한계가 있으며, 비용과 컴퓨팅 성능 등의 문제로 실제 현장에서의 적용은 어려운 상황이다(Raffel et al., 2020).
이러한 문제를 극복하기 위해 많은 연구에서 시소러스(Thesaurus)를 활용하여 단어 간의 관계를 명시적으로 정의하고, 이를 NLP 모델에 반영하려는 시도를 해왔다(Park et al., 2024). 그러나, 기존 시소러스는 단어 간의 관계를 정의하는 데 유용하지만, 도메인 특화 데이터에만 유효하며, 새로운 도메인에서 자연어처리 기술을 개발할 때마다 새로운 시소러스를 구축해야 하는 한계점이 존재한다(Kim and Chi, 2019). 이러한 한계점은 건설산업 텍스트마이닝에 큰 제약조건으로 작용한다.
1.1.2 연구의 목적
본 연구는 건설산업의 텍스트데이터를 분석할 때 매번 새로운 시소러스를 수작업으로 구축해야 하는 한계점을 극복하기 위해 사용자로부터 입력받은 문서를 분석하여 자동으로 시소러스를 구축하는 기술을 개발한다. 연구 결과는 단어들의 동시 등장 및 분산 표현 시소러스로, 주변 단어들과의 연관성을 바탕으로 현재 단어를 정확하게 인식하는데 기여한다. 또한, Co-occurrence, Word2Vec, Cosine Similarity 등 단순하고 가벼운 모델을 사용하여 도메인 특화 시소러스를 개발함으로써 실제 현장에서도 손쉽게 활용할 수 있다. 웹에 공개되어 데이터 수집이 용이한 건설공사 시방서를 활용했다. 또한, 추후 연구에서의 데이터 추가 수집과 연구 범위의 확장성을 고려하여 영어로 작성된 문서들을 분석 대상으로 설정했다.
2. 관련 연구
2.1 시소러스(Thesaurus)
시소러스는 각 용어에 대한 정의를 제공하는 것이 아닌, 동의어(Synonyms), 상위어(Hypernyms), 하위어(Hyponyms) 등 용어 간의 관계를 설명한다(Aitchison et al., 2003). 다양한 정보 검색 방법론에서는 시소러스를 활용하여 질의를 확장하고 더 포괄적인 검색 결과를 도출하고자 했다(Zou et al., 2017). 텍스트 내의 모든 용어를 시소러스에 정의된 피벗(Pivot) 형태로 대체함으로써, 텍스트 분석이 사용자의 분석 의도를 보다 잘 반영하도록 할 수 있다. 일반적으로 특정 도메인에 대한 깊은 지식을 가진 업계 전문가들에 의해 구축되거나(Kim and Chi, 2019), 기존의 동의어 사전을 활용하여 개발된다(Zhang and El-Gohary, 2015).
2.2 Natural Language Processing
텍스트를 분석하는 컴퓨터화된 접근 방식으로 초기에는 문서를 사전 정의한 유형에 따라 분류하여 수많은 문서를 효율적으로 저장 및 관리하기 위한 기술이 개발되었다(Moon et al., 2018; Ji and Lee, 2023). 2010년대 중반 Word2Vec과 Doc2Vec 등 분산 표현(Distributed Representations) 모델이 제안됨에 따라 문서의 내용을 보다 효과적으로 분석할 수 있게 되었고, 키워드 인식, 위험 요인 추출, 리스크 조항 도출, 규정 준수 확인 등 다양한 연구가 수행되었다(Moon et al., 2022a, 2022b; Wu et al., 2022; Zhang and El-Gohary, 2015, 2016, 2021; Zou et al., 2017).
3. 시소러스 개발 과정
본 논문에서는 영미권 각국의 건설공사 시방서 PDF 문서만을 훈련 데이터로 이용해 시소러스를 개발한 후, 개발한 방식을 이용해 다른 도메인의 문서를 input으로 할 시, 해당 도메인의 시소러스가 자동으로 구축될 수 있도록 하고자 한다. Fig. 1을 통해 3장에서 소개할 시소러스 개발 과정을 포함한 전체 연구의 구조를 나타냈다. 3.1절에서 데이터 수집 및 전처리 과정, 3.2절에서 시소러스를 개발하는 각 방식과 과정을 설명할 것이다.
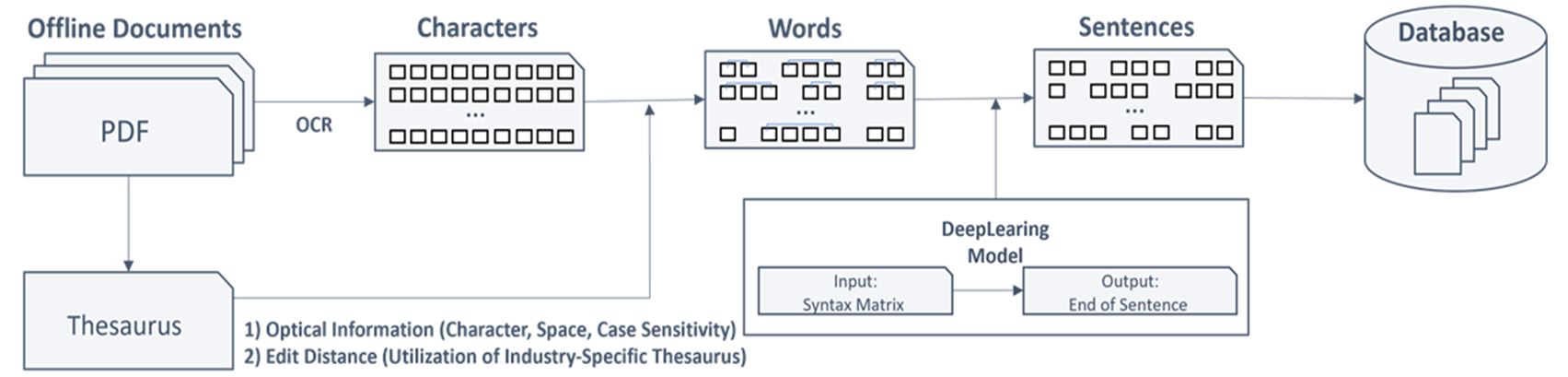
3.1 데이터 수집 및 전처리
본 연구에서 사용한 원본 데이터는 웹에서 쉽게 수집할 수 있는 각국(영미권)의 건설공사 시방서 PDF 파일을 획득했고 데이터 내용은 Table 1에서 확인할 수 있다. Table 1의 55개의 건설공사 시방서 PDF 파일은 컴퓨터에서 내용을 수정하거나 분석할 수 없으므로 각 파일을 코퍼스(Corpus)로 변환하는 과정을 수행했다.
Table 1.
Description of Raw Data
코퍼스란, 대량의 텍스트 데이터 집합을 나타내며, 자연어처리 작업을 수행하는 모델을 훈련할 때 사용된다. 각 PDF 파일을 pyMuPDF의 Fitz 모듈을 사용하여 텍스트 파일로 변환한 뒤, 시소러스가 도메인 용어 간 유의 관계에 집중할 수 있도록 원본 데이터에 존재하는 숫자, 마침표(.)를 제외한 특수기호에 정규식(Regular Expression)을 사용하여 모두 제거했고 모든 단어는 소문자로 변환하여 코퍼스를 구축했다. 각 문장을 토큰화하는 과정에서 마침표를 기준으로 토큰화하므로 마침표는 제거하지 않았다. NLTK(Natural Language Toolkit) 라이브러리를 사용하여 텍스트를 문장으로 토큰화 후, 각 문장을 단어로 토큰화하는 과정을 거쳐 결과를 텍스트 파일(코퍼스)로 저장했다.
3.2 시소러스 구축
본 연구에서는 단어의 동시 등장 단어(Co-occurrence)와 분산 표현(Distributed Representation) 기반 방법을 사용한 2가지 종류의 시소러스를 구축했다.
3.2.1 동시 등장 단어 기반 방식
동시 등장 단어 기반 방식은 두 개의 단어가 한 문장에 많이 등장할수록 중요한 단어일 것이라는 단순한 가정에 기반하여 Word Embedding을 진행한다. 먼저 코퍼스에 대하여 불용어(Stopword) 제거 과정을 통해 유의미한 용어들에 집중하여 관계를 추출할 수 있도록 했고, 코퍼스 내 모든 unique한 단어들에 대하여 등장 순서에 따라 기준 단어로 선정한다.
텍스트 데이터의 모든 문장을 n-grams 접근 방식을 기반으로 토큰화하여 자주 함께 등장하는 용어들을 계산했다. 여러 개의 용어로 구성된 문장을 고려하여 동시 등장 범위인 n의 크기를 기준 단어가 포함된 문장 1개로 설정했다. 기준 단어와 동시 등장하는 유의어에 대해 아래 식을 사용하여 가중치와 빈도를 모두 반영한 유사도를 계산한다.
먼저 가중치를 계산한 방식은 다음과 같다. 한 문장을 범위로 하여 단어별로 인덱스 j를 부여한다. 기준 단어의 j를 0으로 부여하고 양옆으로 거리가 한 단어씩 멀어질 때마다 기준 단어의 인덱스 j에 1씩 더한 값을 해당 단어에 부여했다. 해당 단어의 인덱스 j를 이용하여 식 (1)과 같이 계산한 결과를 각 단어의 가중치 w라고 한다. 빈도는 코퍼스 내에서 특정한 기준 단어와 유의어 1쌍이 반복되어 등장하면 기존 가중치에 새로 등장한 시점에서 계산한 가중치를 누적했는데, 이러한 방식을 통해 최종적으로 누적된 가중치를 유사도로 정의했다.
위와 같은 방식으로 기준 단어와 그에 대한 유사도가 높은 유의어 상위 10개를 유사도와 함께 Table 2와 같은 형태로 텍스트 파일에 저장하여 시소러스를 구축했다.
Table 2.
Thesaurus Structure with Base Words and Synonyms
3.2.2 분산 표현 기반 방식
분산 표현 기반 방식은 Word2Vec과 같은 텍스트의 분포를 학습하는 임베딩 모델(Embedding Model)을 활용하여 문맥 내에서 쓰임새가 유사한 단어들이 서로 관계를 가진다고 인식하는 방식이다(Mikolov et al., 2013a; Mikolov et al., 2013b; Nguyen and Ichise, 2018). 텍스트의 분포에 따라 텍스트를 밀집 벡터(Dense Vector)로 표현하며, 주변 단어들 간의 관계에 따라 임베딩이 이뤄진다. 이를 통해 텍스트의 의미(Semantic Information)를 활용한 시소러스를 구축할 수 있다.
분산 표현 기반 시소러스를 구축하는 과정은 코퍼스에 대하여 불용어(Stopword) 제거 과정을 거친 후, Fig. 2의 구조를 가진 Word2Vec 모델의 Skip-gram을 사용하여 임베딩을 진행했다.
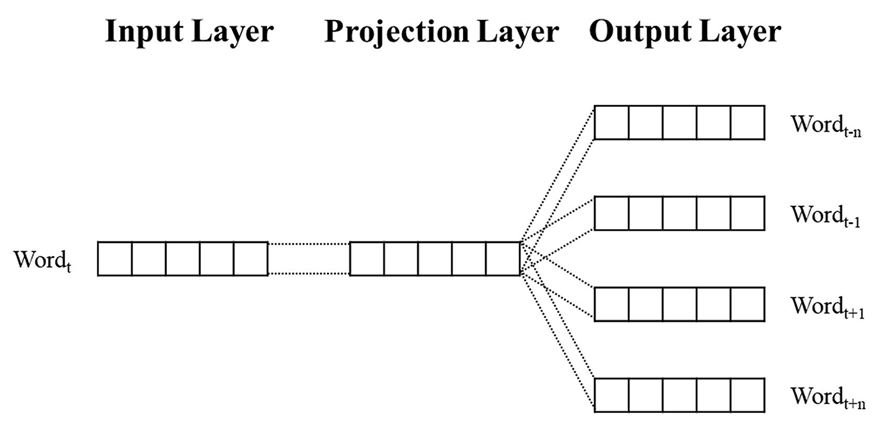
코퍼스의 각 문장을 리스트로 변환 후 전체 코퍼스 리스트에 저장하는 방식의 중첩 리스트를 생성하여 Word2Vec 모델의 학습에 사용했다. Word2Vec 모델을 학습시킬 때, 설정한 Hyperparameter 값은 Table 3과 같고, Word2Vec 모델이 코퍼스 내에서 최소 15번 이상 등장한 단어들에 대해 좌우 5개 단어를 고려하여 주변 단어를 예측하는 방식으로 학습했다.
Table 3.
Hyperparameters types and values of Word2Vec Model
| Hyperparameter | Value |
| Vector Size | 200 |
| Window Size | 5 |
| Minimum Word Count | 15 |
| Number of Workers | 4 |
| Training Algorithm | Skip-gram (sg = 1) |
| Training Epochs | 500 |
모델을 통해 얻은 결과 역시 동시 등장 단어 기반 시소러스와 동일하게 기준 단어와 그에 대한 유사도가 높은 유의어 상위 10개를 유사도와 함께 Table 2와 같은 형태로 텍스트 파일에 저장하여 시소러스를 구축했다.
4. 결과 및 고찰
4.1 시소러스 자동 구축 결과
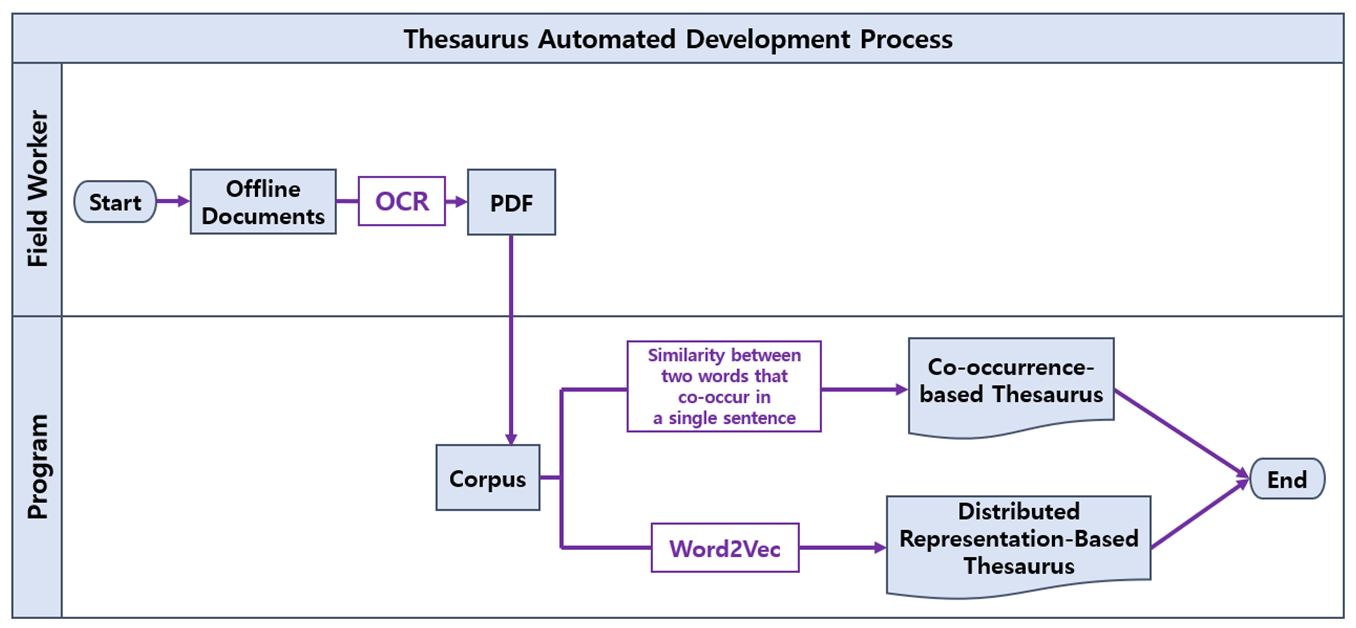
각 시소러스에서 찾은 단어 관계의 개수는 동시 등장 단어 기반 시소러스의 경우는 748,890개이고, 분산 표현 기반 시소러스의 경우에 172,650개의 단어 관계가 형성되어 나타났다. 시소러스 자동 구축 과정은 Fig. 3의 순서도에서 표현한 과정으로 진행되어 시소러스를 구축하여 제공한다. 현장 작업자가 오프라인 문서를 프로그램에 제공하면 프로그램에서 자동으로 문서를 코퍼스로 변환한 후, 동시 등장 단어 기반 시소러스와 분산 표현 기반 시소러스 2가지 형태의 결과를 제공한다.
4.2 시소러스 시각화
구축한 시소러스를 평가하기 위해 단어 간 유의 관계를 시각적으로 확인할 수 있도록 시각화 과정을 수행했다. 시소러스에 존재하는 수십만 개의 단어 관계를 모두 시각화하는 것은 그 관계를 확인하기 어렵기 때문에, 최저 유사도 기준을 설정하여 해당 기준 이상의 유사도를 보이는 관계만을 시각화했다. 네트워크 분석 패키지인 “network”와 동적 시각화 패키지인 “pyvis”을 사용하여 단어 간 관계를 Word Network로 시각화했다. 시각화 결과의 노드(Node)는 단어를 의미하고 에지(Edge)는 단어 간의 유의 관계를 의미한다.
4.2.1 동시 등장 단어 기반 시소러스 시각화
동시 등장 단어 기반 시소러스에서는 동시 등장 단어 쌍이 코퍼스 내에서 여러 문장에서 중복되어 등장하는 경우가 많다. 따라서 유사도의 계산 결과 그 자체로는 1 이상이 나올 수 없지만, 동시 등장 단어 쌍이 중복되어 등장하는 빈도가 높을수록 유사도가 누적되기 때문에 유사도의 값이 매우 크다면 해당 단어 쌍은 코퍼스 내에서 자주 등장했다고 볼 수 있다. 시소러스 상의 모든 관계를 표현하는 것은 시각화의 가시성에 영향이 있어 최저 유사도 기준을 200 이상으로 설정하여 이보다 높은 단어 관계만 시각화될 수 있도록 했다.
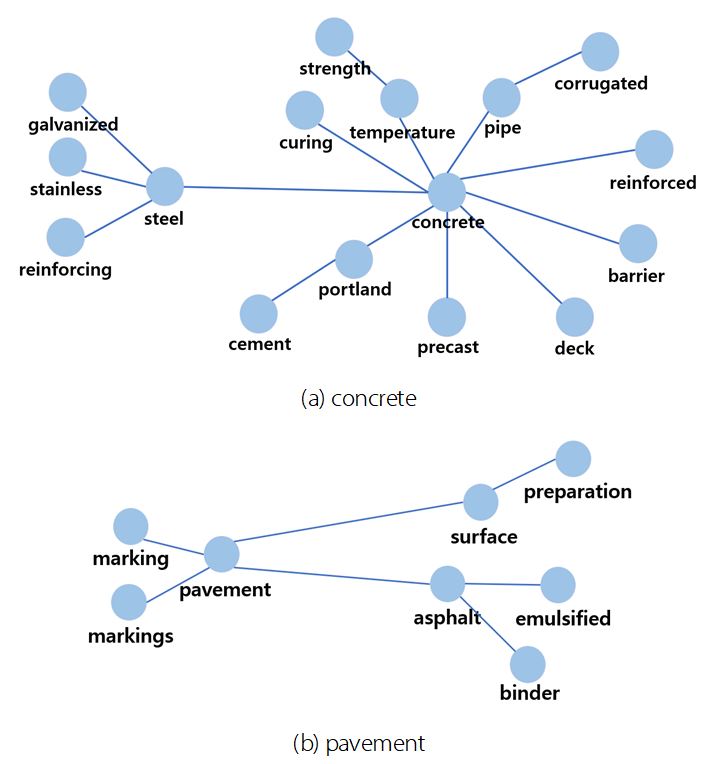
Fig. 4를 보면 시소러스에 등장하는 단어 중 독립적인 관계를 형성한 단어 관계 뭉치들보다 시각화 결과 중심부의 뭉친 부분을 보면 관계를 맺은 단어가 또 다른 단어와 관계를 형성하는 식의 꼬리물기로 이어진 관계로 얽히고설킨 관계가 대다수임을 확인할 수 있다. 시각화 결과 중심부를 확대하여 적절한 관계를 맺고 있는지 확인하기 위해 관계를 복잡하게 형성하고 있는 부분 중 일부를 간략하게 도식화했다.

Fig. 5(a)에서는 콘크리트(concrete)를 중심으로 다양한 단어들이 관계를 형성한 모습을 확인할 수 있다. 콘크리트를 사용해 만드는 구조물과 관련된 단어들과 사전 제작 콘크리트(precast concrete)에 대한 단어, 콘크리트 양생(curing of concrete) 작업에 대한 단어, 철근 콘크리트와 관련된 “reinforced”, “steel”과 같은 단어들 등과 같은 단어들이 “concrete”와 관계를 형성하고 있음을 확인할 수 있다. 또한, “steel”에 대하여 아연 도금 강(galvanized steel), 스테인리스(stainless) 등과 관련된 단어들이 추가적인 관계를 형성한다.
Fig. 5(b)에서는 포장과 관련된 단어들이 관계를 형성하고 있는 모습을 간략화했다. 포장을 의미하는 “pavement”을 중심으로, 도로포장 후 표시 작업인 마킹(marking)과 관련된 단어들이 연결되어 있다. 또한, 도로포장에 사용되는 유화 아스팔트(emulsified asphalt)와 관련한 단어들이 존재한다. 도장 표면처리(surface preparation)와 관련한 단어들이 또 다른 단어 관계 뭉치를 형성하고 있다.
Fig. 5(a)와 Fig. 5(b)을 통해 각 단어가 여러 단어와 관계를 형성하고, 해당 단어들이 또 다른 여러 단어와 관계를 형성하는 형태가 반복되는 것을 확인할 수 있다.
4.2.2 분산 표현 기반 시소러스 시각화
각 단어 간의 관계가 의미론적으로 적절히 형성되었는지 확인하기 위해 분산 표현 기반 시소러스의 시각화를 수행하였다. 해당 시소러스 역시 모든 관계를 표현하는 것은 시각화의 가시성에 영향이 있어 최저 유사도 기준을 0.6 이상으로 설정하여 해당 기준 미만의 단어 관계는 시각화되지 않도록 했다. 최저 유사도 기준을 통해 일정 기준 이상의 단어 간 강한 관계들을 시각화했다.
Fig. 6에서는 소수의 단어를 중심으로 다양한 단어와 서로 복잡하게 관계를 맺고 있는 부분들이 중심부에 있고 독립적으로 여러 단어가 관계를 형성한 단어 뭉치들이 외곽에 자리를 차지하고 있는 것을 볼 수 있다.
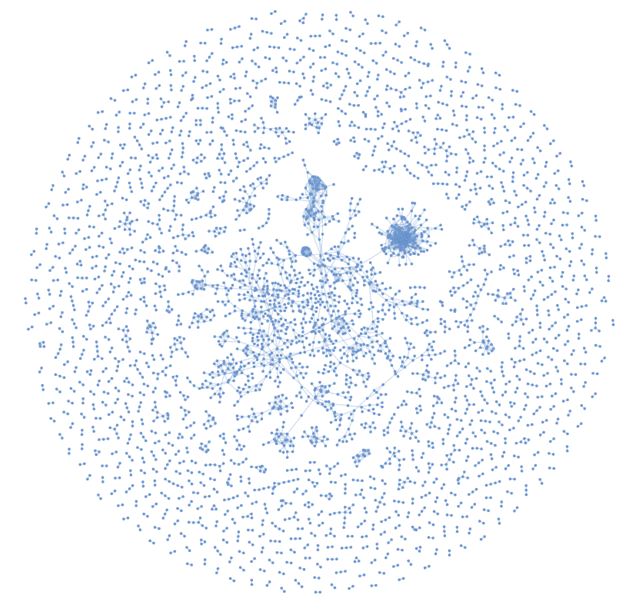
Fig. 7(a)에서는 건물 이음새나 콘크리트 이음부에 주로 작업하는 실리콘 코킹 작업과 관련된 단어들이 서로 관계를 형성하고 있다. 실리콘 코킹 작업이 수행되는 크랙(Crack) 부분에 대한 단어들과 백업제로 손쉽게 코킹(caulking)할 수 있도록 만들어주는 보조재인 Backer Rod, 실링(Sealing) 작업과 관련된 단어들이 관계를 형성하고 있다.
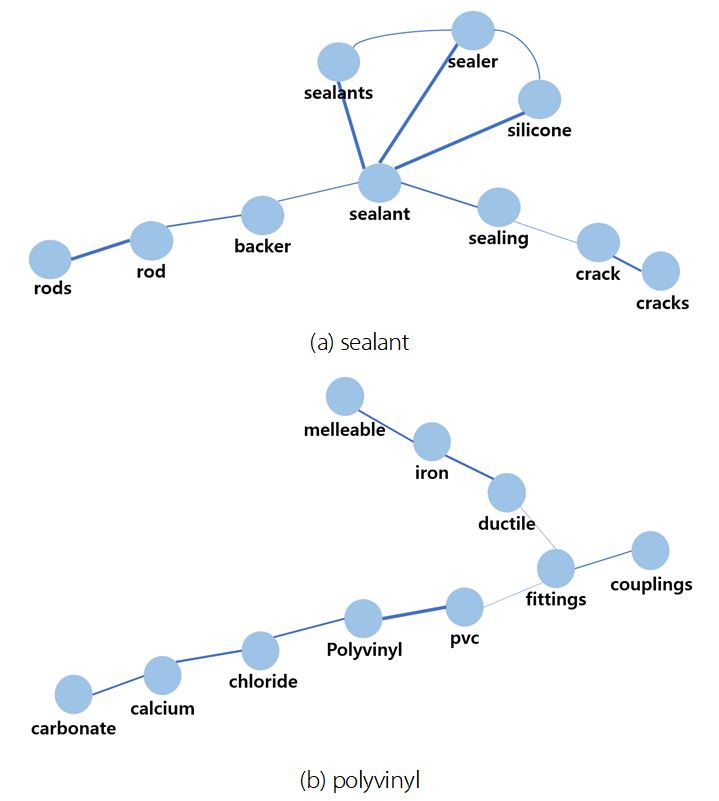
Fig. 7(b)에서는 가단주철(melleable iron)과 연성주철(ductile iron) 가공과 관련된 단어들이 존재한다. 또한, pvc(polyvinyl chloride)와 관련된 단어들이 관계를 형성하고 있고 그와 비슷한 재료나 원료에 대한 단어들이 같이 관계를 형성한다. 이러한 예시를 통해 3.2절의 시소러스 구축 과정을 통해 개발한 시소러스가 의미론적으로 성공적인 구축이 이루어졌다고 판단했다.
4.3 시소러스 활용 방안
본 연구는 55개의 건설공사 시방서로부터 시소러스를 자동으로 구축하고, 자주 사용되는 단어들의 관계를 파악했다. 단어들의 관계는 추후 자연어처리 과정에서 유사한 의미로 사용되지만 서로 다르게 표기되는 단어들을 이해하는 데 도움을 주기 때문에 인공지능 분석 정확도를 향상하는 데 기여할 수 있다.
5. 결 론
건설현장에서 발생하는 문서에는 공정관리, 품질관리, 안전관리 등 현장을 운영하는 과정에서 필요한 경험지식이 담겨있다. 이러한 경험지식을 분석하여 정보를 추출하기 위해 텍스트마이닝 기술이 활용되고 있다. 대규모 언어 모델(LLM)의 성능이 뛰어나지만, 건설산업 특화 용어 및 표현을 정확히 이해하지 못하는 한계점 등이 존재한다. 따라서, 건설산업이라는 특수한 환경에 적용되기 위해서는 보다 실질적이고 구체적인 문제의 해결이 요구된다. 이러한 문제를 극복하고 건설산업 텍스트마이닝의 정확도를 향상하기 위해 많은 연구자가 시소러스를 활용하고 있다.
본 연구는 시소러스의 활용성을 향상하기 위해 입력받은 문서 데이터의 도메인 특화 시소러스를 자동으로 구축하는 방법을 제안했다. 데이터 수집이 용이한 건설공사 시방서를 사용하여 실험을 진행한 결과, Co-occurrence를 바탕으로 748,890개의 동시 등장 단어 기반 시소러스를 구축했고, Word2Vec과 Cosine Similarity를 활용하여 172,650개의 분산 표현 기반 시소러스를 구축했다. 또한, Word Network를 사용하여 단어 간의 연관성을 파악해 시각화했다. 이를 통해 텍스트마이닝 과정에서 특정 단어의 인식에 실패한 경우, 주변 등장 단어들을 바탕으로 오인식한 단어를 정확하게 유추할 수 있다.
건설산업 텍스트마이닝을 위한 시소러스 구축 시, 기존 구축 방식에서는 새로운 도메인에 대해 별도의 시소러스를 새로 개발해야 했으나, 본 연구에서는 입력데이터의 도메인 특성을 파악하여 시소러스를 자동 구축하는 방법을 제시하였다. 또한, 본 연구에서 개발한 시소러스를 활용하면, 텍스트마이닝 결과에 대한 정확한 검증과 수정을 할 수 있다. 이는 건설산업 문서의 다양한 용어와 표현을 정확히 이해하고 분석할 수 있게 해주며, 시소러스를 통한 불확실한 결과 수정이 가능하므로 정확도 높은 데이터셋을 구축할 수 있다. 이러한 검증된 데이터셋을 활용하면, 건설 특화 표현과 용어가 학습된 대규모 언어 모델을 개발할 수 있다. 이를 통해 도메인 특화 질의응답 시스템 등 다양한 작업에 대한 성능 향상을 기대할 수 있다.
후속 연구로는 본 연구에서 구축한 시소러스를 활용하여 단어 수정 알고리즘을 개발하고, 자동화된 분석 시스템을 구현하고자 한다. 또한, 수기로 작성된 건설현장 문서에 OCR을 적용하여 추출한 텍스트 데이터에 본 연구에서 구축한 시소러스를 적용하여 인식 오류를 수정한 후, 유의미한 정보를 추출하는 연구를 진행하고자 한다.
