

1. Introduction
1.1 Background
1.2 Literature review
1.3 Research gap and objective
2. Material and method
2.1 Environment description
2.2 RL training
2.3 Metrics for learning
3. Results and Discussion
4. Conclusion
1. Introduction
1.1 Background
Automation in architecture is in its early stages and requires the integration of planning modules for design. Additionally, robot arms must be capable of grasping objects with complex orientations to advance further. Robotic grasping is fundamental to various industrial and other field tasks. As it is based on objects shapes, position and orientation or pose, there are many variants of it: 2D, 3D and 6D pose estimation and grasping to utilize it in stacking, pick and place or any other complex robotic task. This encompasses 2D, 3D, and 6D pose estimation and grasping for tasks like stacking and pick-and-place operations. Although previous studies have addressed grasping objects of various shapes and orientations, there is a lack of research on grasping objects with complex poses that combine azimuthal and altitude angles. Most studies have focused solely on azimuthal angles and often involve grasping objects from a fixed direction. Therefore, it is crucial to address this knowledge gap regarding the grasping of objects in complex poses and to explore RL-based solutions in robotic grasping for architectural applications. In our study, we aim to grasp objects with complex poses using a modified SAC algorithm with a six-joint industrial robot arm. We formulated a problem statement involving object grasping with randomly generated poses around the x and z axes. Two variants of modified SAC, along with a baseline SAC (Li et al., 2022; Shahid et al., 2022), were applied to train the robot to grasp bricks.
1.2 Literature review
Some studies have explored object grasping with various objectives without using RL to achieve the target pose. Choi et al. (2018) employed a 3D Convolutional Neural Network (CNN) to achieve an 87% success rate in grasping unknown objects with a soft hand. Liang-shan et al. (2019) introduced a multi-stage grasping method using undirected graphs for posture matching and robot motion node generation. Similarly, Deng et al. (2020) developed a self-supervised algorithm for 6D pose estimation of objects through continuous robot interaction and image collection. Fu et al. (2020) utilized point-pair features to estimate grasping poses of rigid objects, demonstrating high success rates in real environments. Cheng et al. (2021) estimated 3-Degrees of Freedom (DOF) grasps for various-sized objects using a single RGB image, training their model on the Cornell Grasp dataset with favorable real-time results. De-Oliveira et al. (2021) presented a 6D grasping method with a region generation algorithm, generalizable for various shapes without retraining. Li et al. (2021) used You Only Look Once 4 (YOLO4) and GrabCut algorithms to improve grasping success for a mobile robot arm by identifying and segmenting objects. Junare et al. (2022) introduced a deep learning-based model for grasping objects with a 5DOF robotic arm. Li et al. (2023) enhanced grasp detection in cluttered environments using a novel sampling method for generating point proposals. Liu et al. (2023) proposed a dense pixel-wise prediction model for industrial parts' pose estimation, showing robustness in cluttered environments through key point detection and the uncertainty Perspective-n-Point (PnP) method. Wang et al. (2023) developed a pose estimation scheme using Convolutional Block Attention Module (CBAM) and Pyramid pooling Module (PPM) algorithms for differently shaped objects. Finally, Liu et al. (2024) introduced a Bidirectional Deep Residual Fusion Network (BDR6D) for 6D pose estimation, integrating RGB and depth information with the SuperPoint-FPS keypoint algorithm. A significant limitation of these studies is their reliance on pose estimation and object grasping with planar orientations, excluding the use of reinforcement learning.
Several studies have applied reinforcement learning (RL) to robotic arm grasping applications. For instance, Park et al. (2020) developed an intelligent robot gripping system using CAD files and 3D scanned point clouds, employing Proximal Policy Optimization (PPO) as the RL algorithm, and demonstrated strong performance in simulations. Similarly, Al-Shanoon and Lang (2021) presented a technique for grasping unfamiliar objects of various shapes using DenseNet and Deep Q Network (DQN), with their deep reinforcement grasp policy (DRGP) providing Q values and orientation heatmaps for image pixels. Mohammed et al. (2021) introduced the Multi-View Change Observation-Based Approach (MV-COBA) for grasping occluded or tightly packed objects using Q learning, achieving a promising success rate in simulations with images from two cameras. Shukla et al. (2020) addressed intelligent object manipulation by decomposing it into position and orientation learning, utilizing a genetic algorithm, a regression-based method, and a pseudoinverse model for position, and RL for orientation. Li et al. (2022) proposed a data-driven approach to generate contact points on an object's surface using a multi-finger hand gripper, comparing its efficiency with EfficientGrasp and UniGrasp methods. Liu et al. (2022) developed a digital twin-based solution for industrial object grasping with DQN, showing higher success rates with transfer learning compared to direct real environment training. Shahid et al. (2022) compared PPO and SAC RL algorithms for grasping and lifting objects of three shapes, transferring the learned behavior to a real robot using zero-shot transfer for various object positions and configurations. Wang et al. (2022) introduced a hierarchical framework for collision-free grasping with partial point cloud observations, incorporating plan selection and an option classifier within a Hierarchical Grasping Policy (HGP). Zuo et al. (2023) presented a graph-based Deep RL approach for exploring and manipulating invisible objects, using explorer and coordinator modules with feature extractor inputs, achieving commendable success rates in both simulated and real environments. A notable limitation in these studies is their focus on object grasping with simple poses, without utilizing reinforcement learning to achieve the target grasping pose.
1.3 Research gap and objective
Previous studies on computer vision models for pose estimation and grasping primarily used images as input. However, these studies have several gaps. They considered only planar poses of objects involving azimuthal angles, neglecting complex 3D angles. Additionally, RL was rarely applied, and when used, it was limited to either pose estimation or position identification, followed by grasping with inverse kinematics or other methods. Thus, it is crucial to explore how a robotic agent can reach complex object poses and grasp them using RL in the architectural domain.
To address the gap, we examine the efficacy of the DRL algorithm SAC and its modified versions in enabling a robotic arm to reach complex grasping poses with known poses (via prior vision estimation). We hypothesize that reaching complex object poses, determined by vision, is a challenging task that standard RL algorithms cannot easily accomplish. Our focus is on using self-learning to achieve the target grasping pose. We implemented SAC and two of its variants to evaluate their performance in reaching the target pose. Our main contributions to the existing research are summarized as follows:
•We introduce, for the first time, the self-training of robot arm to achieve a complex pose of brick in an architectural site, showcasing real-world scenarios.
•We introduce modified SAC with two variants, marking the first application of such variations in architectural contexts and comparing their effectiveness.
2. Material and method
This study focused on post-pose estimation grasping using RL. A KUKA robot arm was employed to grasp bricks with complex poses within a large search volume in a simulation space. RoboDK served as the simulation platform, and Python (version 3.11.7) was used for the training of RL agents. This study focused on achieving brick grasping at randomly generated poses within a specified threshold distance and angle.
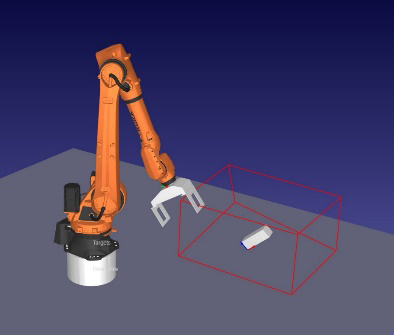
Object 6D pose was set randomly in simulation platform and robot arm search for this pose under the RL training by adjusting its joint angles. Python was used as a link between RoboDK and agent training in Jupyter notebook. Fig. 1 shows the developed framework of this study and Fig. 2 depicts box and gripper dimensions. To model the environment, we utilized the most widely used ‘OpenAI Gym’ library (version 0.26.2) and linked it with Robodk physics software (version 5.6.1) for the robotic arm simulation. Torch (version 2.0.1) and StableBaselines3 (version 2.0.0) were utilized as the RL libraries used in this proposed scheme and agents were trained with three variants of SAC algorithms. In this setup, the agent models were based on continuous observation and action space. Search space for target grasping position and orientation; and search volume by robotic arm are presented in Fig. 3, which also depicts the experimental setup for this scheme.
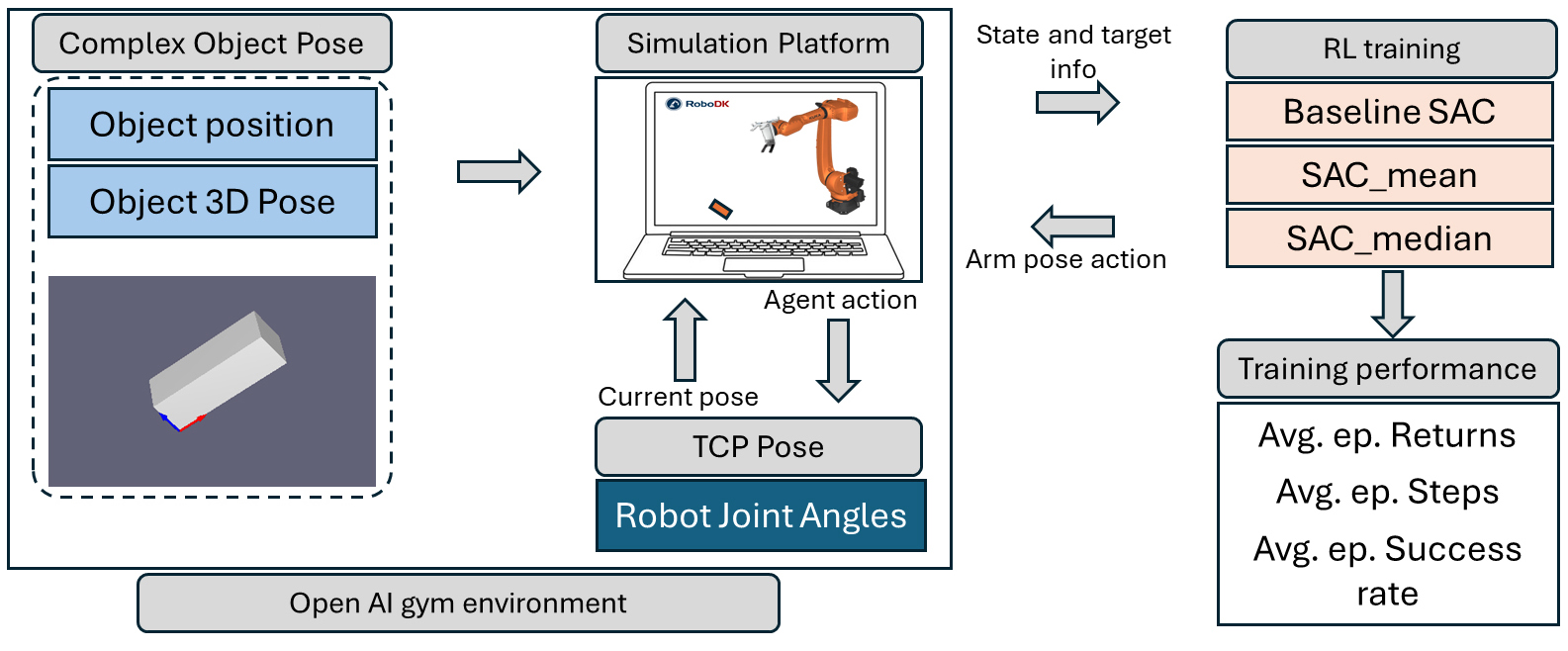
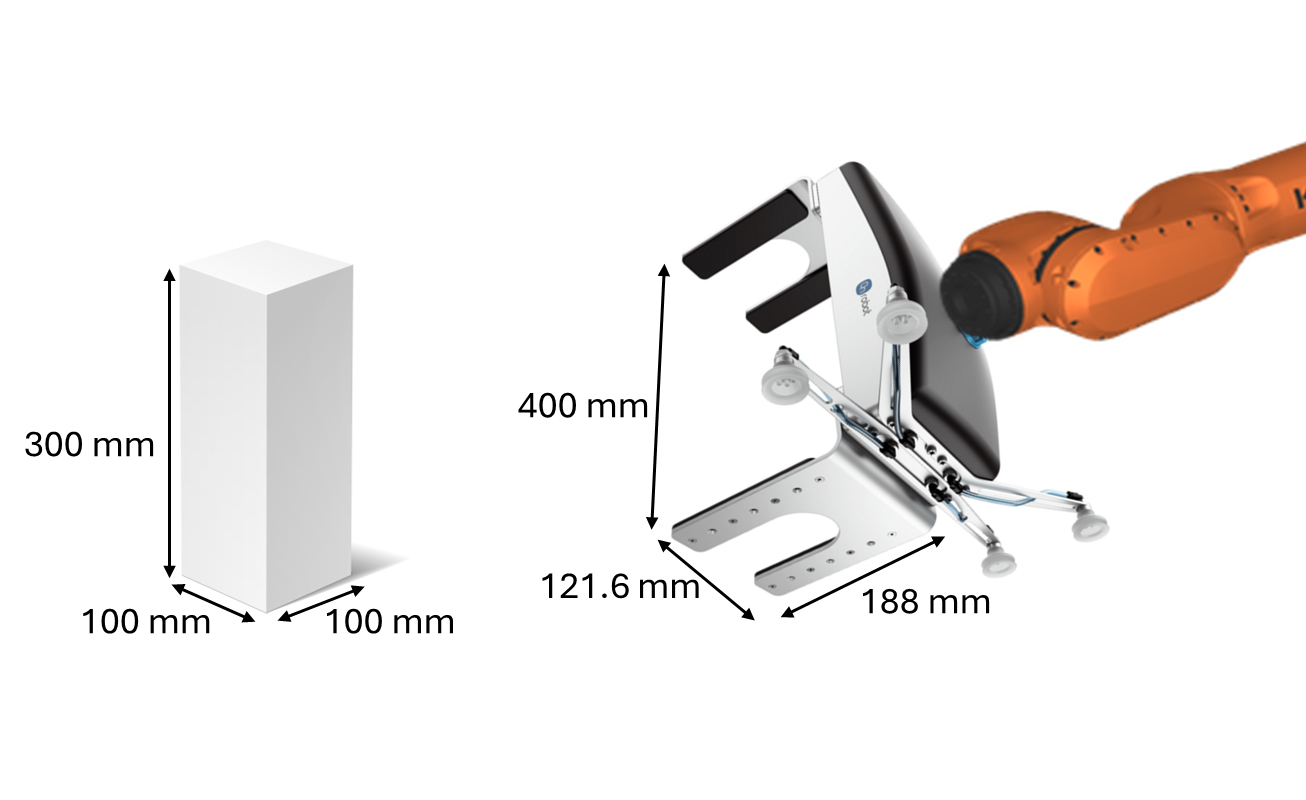
Grasping objects in close proximity with a robot arm is essential for most robotic tasks and becomes more complex with increased DOF. Higher DOF increases the likelihood of undesirable postures in Cartesian coordinates, complicating RL in these coordinates. Thus, joint angles are preferable for RL, despite the complexity of managing a larger number of joints. Joint angles are better suited for continuous space problems, where determining precise combinations in discrete space is challenging. In our research, we used a KUKA KR50 R2500 robot arm of 6 DOF and a 2500 mm reach with OnRobot 2FGP20 gripper. We focused on grasping target search within a 10 mm Cartesian position range and a 15-degree orientation range from the target pose. Detailed task descriptions are provided in the following sub-sections.
2.1 Environment description
In this study, we randomly positioned and oriented a brick, fixing one corner as the base position point and considering rotations around the z and x axes as altitude and azimuth angles. The target pose was defined as a point 200 mm from the base position, maintaining the same 3D orientation as the brick. Thus, the target pose included both target position and target orientation. The search volume for the target position was within the ranges: x: 800-2000 mm, y: 400-1400 mm, and z: 200-600 mm, with azimuth and altitude angles ranging from -90 to 0 degrees and 0 to 90 degrees, respectively. Observation space s ∈ ℝ12 was a 12-dimensional array which encompassed 6 joint angles of robot arm, 3 cartesian coordinates of target position and 3 rotational axis values; and action space a ∈ ℝ6 was 6 dimensional which comprised of angular change in each joint angles. Table 1 presents the ranges of observation space and action space variables.
Table 1.
Observation and action space ranges
Reward function: The reward function for this task was designed to depend on both distance and orientation. A reward of +0.2 was given if the end effector was within 10 mm of the target position and 15 degrees of the target orientation. The reward decreased exponentially as the end effector moved further from the target pose. Distance was measured using the Euclidean norm, while rotational distance was calculated from the sum of azimuth and altitude angles between the target and the end effector poses, adjusted via six joint angles in RoboDK software. A high positive reward of +1 was applied if both distance and rotational distance reward were positive. Additionally, if the robot arm exceeded predefined joint angle ranges, a penalty of -1 was applied.
2.2 RL training
Three RL algorithms were utilized in training for this task of complex grasping. Standard SAC was used as the baseline which utilized two critic and target critic networks and the minimum of the critic’s Q value was selected for the value network and critic network loss calculation. In this method, policy update is done by gradient ascent and critic update by gradient descent of loss functions of value and Q. Policy objective function, and critic loss functions are as follows.
here, 𝜙 and 𝜙' are value function main and target network parameters, θ1, θ2 are main Q network parameters, and 𝜙 is the policy network parameter. K is the minibatch size. and are the target value of value and Q value for critic loss function evaluation. Action a in equation 3 is a parametrized neural network ‘f’ output with sampled noise, . Similar to other algorithms, in this also target network parameters will be updated by soft updating mechanism.
Other two variants of SAC utilized 5 critic and target critic networks with one actor network and mean and median of the 5 Q values from the critic network for the critic and value network loss and updating but rest of the functioning is the same as baseline SAC. Eq. 9 and 10 depict the target values for value network and critic network for SAC version with meanwhile eq.10 and 11 depict that of SAC median version.
In this study, we employed a fixed initial position and a randomly generated target pose for each episode. Episode termination occurred either when the maximum number of steps was reached, or the target was achieved. We used the stable_baseline3 (SB3) library to implement the algorithms and trained the model for 15,000 episodes. Each episode comprised T (=384) discrete time-steps, concluding at T or upon reaching the predefined threshold pose. SB3 was used to preserve model parameters, track model loss, and standardize the environment before training. Post-training, models were tested using saved parameters and normalization statistics to evaluate rewards, steps taken, success rates, and distances with rotational distances from the target.
Table 2 presents the hyperparameter ranges and the optimal values for RL algorithms used. Optimal hyperparameters were selected through manual searches within specified ranges. All algorithms employed a decaying learning rate, determined through iterative trials, ranging from 0.0008 to 0.0003. Additionally, the network structure, consisting of two Multilayer perceptions (MLPs), was established via trial and error.
Table 2.
Hyperparameters range and best values
2.3 Metrics for learning
The assessment of the agents' training performance tracked three primary metrics: average episodic return, average episodic steps, and average success rate. In contrast, the testing rollouts focused on measuring the algorithm's effectiveness in achieving the target pose. We implemented a 25-episode evaluation period, averaging episodic rewards, steps, and success rates as key performance indicators, and tracked training loss for enhanced evaluation. These three performance measures illustrate an increase in episode returns, a reduction in steps required to achieve the target, and an improvement in the success rate of target achievement through training, thereby inherently reflecting the degree of training success. Using a sliding window averaging approach, we observed these metrics and ran each algorithm five times, presenting mean and 95% confidence interval results across these runs. These indicators revealed the training convergence speed and effectiveness. For testing, we plotted the distance from target positions and rotation distance from the target pose to analyze variation and significance. For this study, a 11th generation i7 PC with 32 GB RAM and GeForce GTX 1650 GPU is used with installed windows 11.
3. Results and Discussion
In this study, performance was evaluated using three metrics: episodic rewards, episodic steps, and success rate, which measure variations across training episodes. Additionally, the final distance and rotational distance from the target pose were used to assess the trained agent's end solution.
Fig. 4(a), (b), and (c) show the fluctuations in average episodic returns, average episodic steps, and average success rate over the training period of 15,000 episodes for a target-reaching task. Each plot displayed solid lines for episodic mean values and transparent regions for 95% confidence intervals at evaluation points (every 25 episodes). The baseline SAC algorithm converged more slowly than the two SAC variants. The mean and median variance SAC variants exhibited similar and less variable performance across all three metrics. In contrast, the baseline SAC showed higher variation in success rate and steps, with only minor differences in rewards compared to the SAC variants. Up to 100 evaluation periods, all algorithms performed similarly, but the SAC variants outperformed the baseline SAC thereafter. Average episodic rewards stabilized within 150 evaluation periods. However, steps and success rates continued to vary, indicating the agent's attempts to achieve the target with minimal differences but not consistently reaching the success threshold. The baseline SAC required more steps to reach the target, while the SAC variants achieved more successful trajectories with fewer steps.
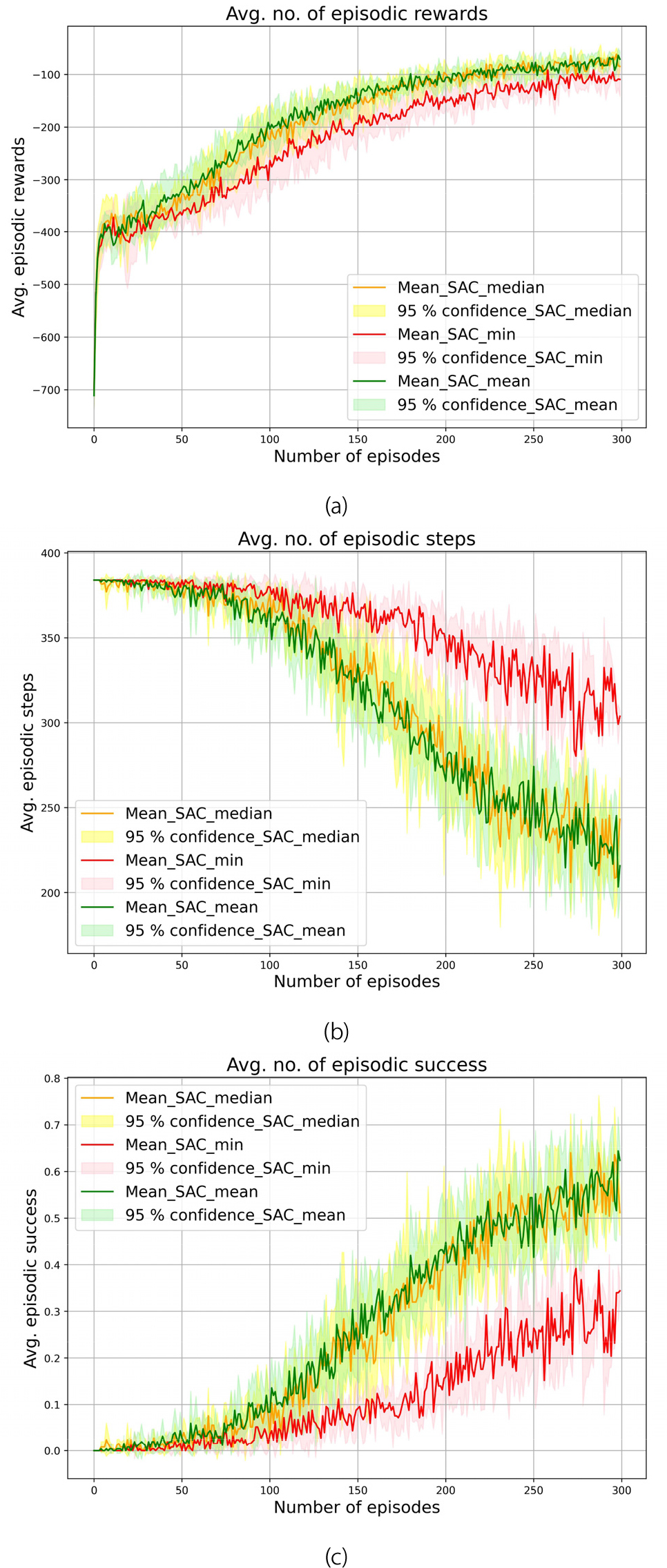
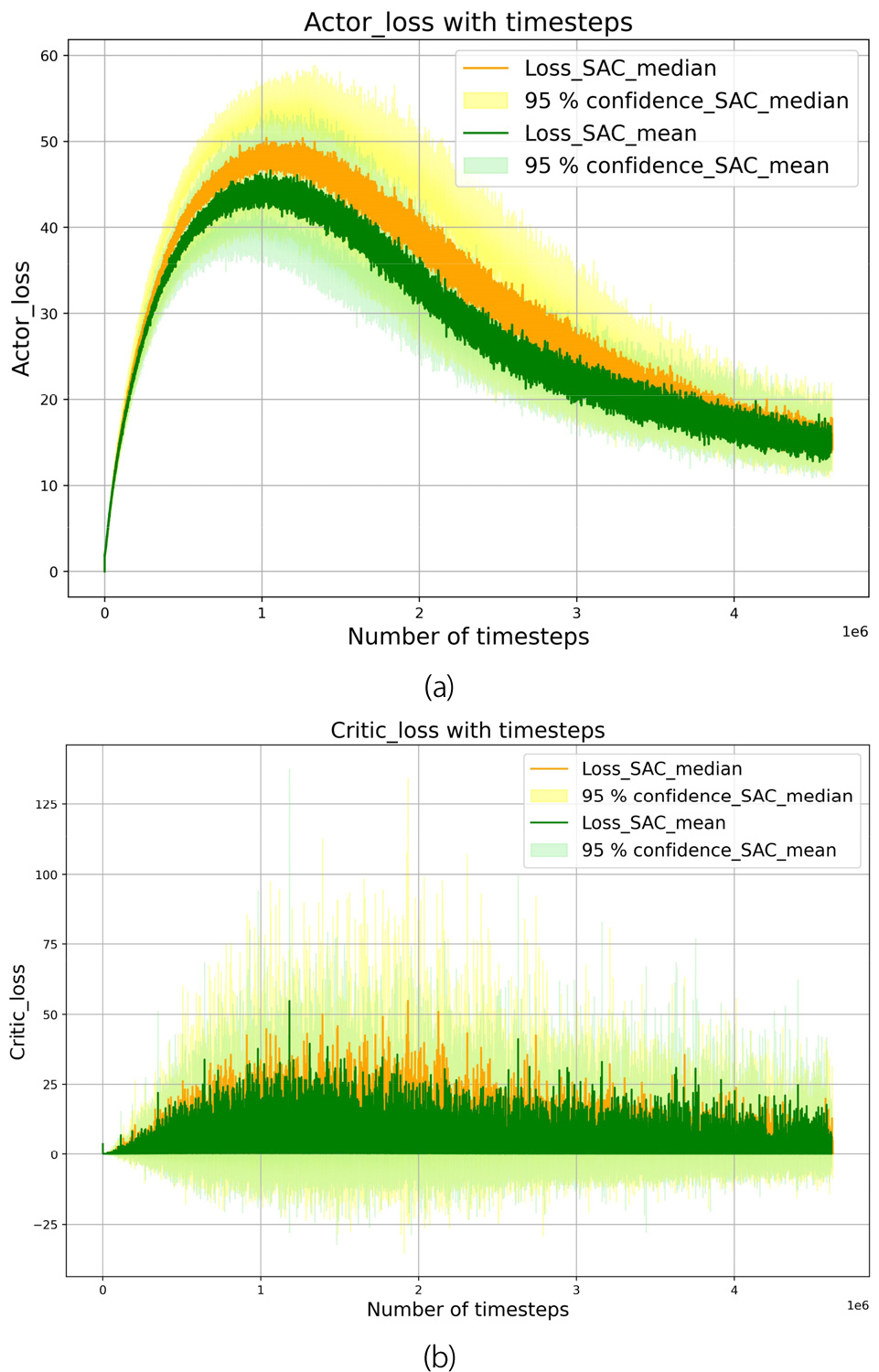
Fig. 5 presents the training period's loss for the SAC median and mean variant algorithms, with actor losses in Fig. 5(a) and critic losses in Fig. 5(b). Initially, both losses increased until 1.2 million time-steps before decreasing, reaching their minimum values around 4 million time-steps. The mean variant demonstrates slightly better performance, achieving faster loss reduction by approximately 0.2 million time-steps compared to the median variant.
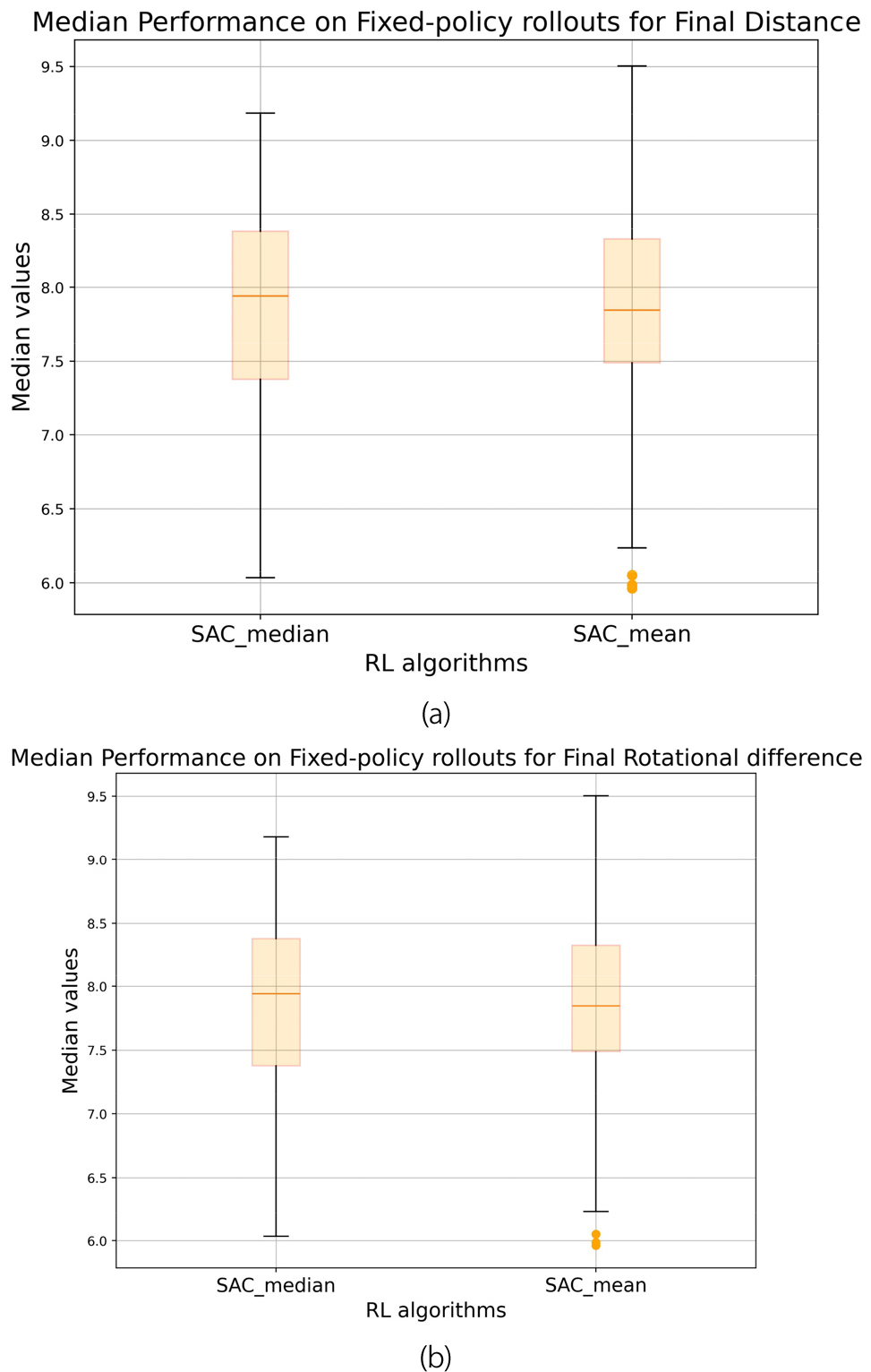
In addition to training outcomes, Fig. 6(a) and (b) depicted testing rollouts of two variants, showcasing the distance and rotational deviation from the target grasp pose. During testing rollouts, the agent's proximity to the target pose was assessed based on distance (in mm) and rotational deviation (in degrees). These parameters were automatically evaluated at the end of each episode to determine how closely the agent approached the target pose. It is apparent that both SAC variants achieve similar performance in grasping the object, with slight superiority observed in the mean version. The median variant showed a wider range of grasp poses with values that were more closely clustered. In contrast, the mean variant displayed a right-skewed distribution, with most values falling below 8 mm in distance and 7.5 degrees in target pose angle differences.
Due to the challenge posed by a low threshold grasp pose, none of the agents achieved complete training within 15000 episodes. However, SAC variants exhibited a favorable success rate of 60% and consistent episodic rewards. Towards the end of training, SAC variants exhibited an upward trend in performance, contrasting with the relatively stable trajectory of the SAC baseline. This suggests that with additional episodes, SAC variants are likely to achieve higher success rates compared to the baseline. Only successful rollouts were considered for performance evaluation, revealing that both SAC variants achieved similar end grasp poses with minimal deviation from the target pose. This study serves as a foundational step for future research in learning-based grasping of objects with complex poses using robotic arms. Grasping serves as a fundamental task in various engineering applications, including pick-and-place, stacking, and holding tasks. These applications rely on effective grasping techniques for successful completion. As a fundamental task in various robotic applications across engineering domains, this implementation can provide significant benefits to each field. The SAC algorithm, an offline Actor-critic method, can be improved by incorporating multiple critic networks. This enhancement involves using mean or median values instead of minimum values to evaluate the target value of the value function, particularly in complex pose grasping tasks within a specified architecture.
4. Conclusion
Despite the apparent ease of grasping objects in large spaces after determining their pose through vision methods, challenges arise due to precise matching in 6D space. Our study achieved success in achieving complex target grasp poses with a robot arm within a considerable search volume. We employed two variants of the SAC algorithm with baseline SAC. Results indicated a 35% success rate for baseline SAC, contrasting with a 60% success rate for the modified versions, supporting our hypothesis. The disparity in success rate becomes evident due to task complexity, with minimal distinction between baseline and modified versions in easier tasks, posing visualization challenges. Further training episodes could potentially enhance the success rates of SAC variants as these are heading up at the end of the training while baseline is flat. A notable limitation of this study was the exclusion of pose estimation for complete grasping of objects with complex poses, such as a brick. Future research could extend this work by integrating vision-based pose estimation methods to enable comprehensive object grasping.
