

1. 서 론
2. 선행연구 분석
2.1 가상물리환경 기반 강화학습
2.2 강화학습에서의 표본 효율성
2.3 표본 효율성 향상을 위한 모방학습
3. DRL 모형 개발
3.1 가상물리환경에서의 크레인 및 작업 정의
3.2 상태 공간 및 보상함수
3.3 정책 네트워크
4. 실 험
4.1 실험 설정
4.2 결과 및 논의
5. 결 론
1. 서 론
건설 크레인의 자율운행 기술은 건설현장의 생산성과 안전성을 향상시킬 수 있는 기술로써 큰 주목을 받고 있다. 크레인 운행 작업은 중량물의 수직 이동, 수평 이동 및 흔들림 억제 등으로 구성(Wu and Xia, 2014)되어 있으며, 그 중 흔들림 억제는 안전사고 방지와 품질확보에 있어 매우 중요한 작업이다(Fang and Cho, 2017; Ramli et al., 2017). 하지만 시스템 제어 측면에서 크레인의 흔들림 억제 작업은 크레인의 조작 가능한 동작의 수보다 중량물 움직임의 자유도가 더 큰 과소작동 시스템(underactuated system)으로 분류되며, 진자운동을 하는 중량물의 운동이 케이블을 활용하여 간접 제어되기 때문에 시간 지연이 발생한다. 따라서 크레인의 수평 및 수직 이동과 비교하여 제어에 어려움이 있다(Sawodny et al., 2002).
기계장비 등의 자율운행 시스템 개발을 위해 심층 강화학습(Deep Reinforcement Learning, DRL) 프레임워크가 널리 활용되고 있다(Zhao et al., 2020; Sallab et al., 2017). 하지만 흔들림 억제 작업에서의 크레인의 운동학적 특성은 강화학습 모형의 정책네트워크 학습 시 표본 효율성(sample efficiency)이 저하하는 문제가 발생시킬 수 있다. 표본 효율성은 강화학습 모형이 목표 성능 확보에 있어 필요한 표본 수와 관계가 있으며(Botvinick et al., 2019), 낮은 표본 효율성은 학습 성능과 시간에 부정적인 영향을 미칠 수 있다(Yu, 2018; Kiran et al., 2021).
따라서 본 연구는 크레인의 흔들림을 억제하기 위한 강화학습 기반 자율운행 기술 개발에 있어 표본 효율성을 향상시키는 학습방식을 분석하는 것을 목표로 한다. 이를 위해 크레인의 물리적, 운동역학적 특성을 모사하는 가상물리환경을 구축하고, 강화학습 알고리즘인 근위 정책 최적화(Proximal Policy Optimization, PPO)와 역강화학습(Inverse Reinforcement Learning, IRL) 알고리즘인 생성적 적대 모방 학습(Generative Adversarial Imitation Learning, GAIL)을 활용하여 표본 효율성에 미치는 영향에 대해 분석한다.
2. 선행연구 분석
2.1 가상물리환경 기반 강화학습
강화학습을 활용해 자율화 시스템을 훈련시키기 위해서는 다양성이 높은 데이터셋을 활용해야 하며, 실제 환경에서 원활하게 작동 가능한 행동을 학습하기 위해서는 다량의 데이터가 필요하다(Shah et al., 2018). 하지만 실제 환경에서 강화학습이 탐색과 활용을 통해 다양성이 높은 상황을 경험하고 훈련하기에는 높은 비용이 발생하며, 특히 건설현장에서는 안전성이라는 한계점이 남아있다(Matsumoto et al., 2020). 따라서 현실과 유사한 원리로 작동하는 가상물리환경을 활용하여 다양한 상황을 재현하여 훈련을 하는 방식에 대해서 많은 연구가 진행되고 있다.
Alex Dosovitskiy(2017)는 Unreal Engine 4 기반의, 도시 환경에서의 자동차 자율주행 연구를 위한 시뮬레이터 CARLA를 제안했다. 이 연구에서 다양한 도시 레이아웃, 건물, 차량 모델링 및 센서와 유연한 환경 조건 설정을 바탕으로 Classical Module Pipeline, End-to-End, 모방학습의 3가지 학습에서 유의미한 성능 개선과 함께 자율주행 연구를 위한 플랫폼의 유용성을 검증했다. Savva et al.(2017)은 복잡한 실내 환경에서의 경로 및 목표 탐색을 위한 시뮬레이터인 MINOS를 제안함으로써 데이터의 다양성을 위해 75만개의 방 구조를 포함하는 SNUCG 데이터셋을 활용했으며, 시각, 거리 측정, 충돌 감지 등 다양한 센서를 조합한 Multi-Sensory의 효율성을 검증했다. Rong et al.(2020)은 End-to-End 네트워크를 활용하는 강화학습을 위한 자율주행용 고화질 시뮬레이터인 LGSVL을 제안했다.
이처럼 강화학습 기반 자율운행 모형 개발에 소요되는 비용과 시간을 줄이기 위해 가상물리환경에 기반한 다양한 형태의 시뮬레이터들이 개발되고 있으며, 이는 실제 환경의 제약적 상황으로 인해 탐색이 제한된 영역까지 충분히 탐색하고 학습하게 함으로써 강화학습 모형이 보다 높은 학습성능을 얻을 수 있음을 보여주고 있다. 본 연구에서는 크레인의 강화학습 모델 개발을 위하여 Unity와 ML-Agents를 활용하여 가상 시뮬레이션 환경을 구현하고(Juliani et al., 2018), 강화학습 모형 개발 및 실험을 수행한다.
2.2 강화학습에서의 표본 효율성
흔들림 억제 작업은 중량물을 목적지에 정확히 위치시키고 체결 작업을 위해 하중 흔들림을 제거하는 작업이다. 크레인은 중량물 인양을 위해 케이블을 사용하기 때문에 중량물은 크레인의 트롤리를 중심으로 진자운동을 하며, 위치 및 운동에너지가 교환되는 과정에서 3방향의 병진운동과 3축 회전운동이 동시에 발생한다. 반면 중량물의 흔들림 제어를 위해 크레인은 수평 2방향(좌/우, 앞/뒤)으로만 동작이 가능하기 때문에, 운동학적 측면에서 제어의 자유도가 더 작은 과소작동 시스템이다(Sawodny et al., 2002). 이것은 크레인이 동작할 때 탑재하중의 흔들림을 발생시키고 중량물의 위치와 운동상태를 예측하기 어렵게 만든다. 예를 들면, 갠트리 크레인이 전진할 때 탑재하중의 위치변화는 관성에 의해 지연되기도 하며, 크레인의 예측 범위 보다 앞서기도 한다(Yang et al., 2019).
심층강화학습은 특정 상태(예: 중량물의 운동)와 선택된 행동(예: 크레인의 제어)으로 부터 기대할 수 있는 보상(예: 중량물의 흔들림)을 최대화할 수 있는 상태와 행동 간 관계를 정의하는 정책네트워크의 학습을 목적으로 하고 있다. 하지만 위에서 언급한 흔들림 억제 시스템에서는 어떤 상태-행동 쌍에 대해 획득가능한 보상이 다양하게 존재할 수 있으며, 이것은 정책네트워크가 선택한 행동분포의 분산을 증가시킬 수 있다. 이러한 특성은 정책네트워크의 학습에 있어 더 많은 표본을 필요하게 하거나 학습성능을 크게 저하시킬 수 있다. 즉, 크레인의 운동학적 특성은 표본에서 행동과 상태 사이의 분포를 복잡하게 하므로 결과적으로 강화학습의 표본 효율성 문제를 악화시킨다.
2.3 표본 효율성 향상을 위한 모방학습
표본 효율성 개선을 위해 모방학습(Imitation Learning)이 활발하게 연구되고 있다(Kiran et al., 2021). 모방학습은 에이전트가 전문가의 행동을 모방하며 학습을 수행하는 방법으로, 상태공간과 전이함수가 복잡하게 정의되는 문제에서 표본 효율성을 크게 개선할 수 있다(Kober and Peters, 2010).
모방학습에는 전문가의 행동으로 정책네트워크를 직접 학습시키는 행동복제(behavior cloning) 방식과 보상함수를 개선하여 최종적으로 정책네트워크를 효율적으로 학습시키는 역강화학습이 있다. 행동복제 방식은 강화학습 모델 성능 확보를 위해서는 많은 수의 전문가 시연 데이터(expert demonstration data)가 필요하며, 전문가 시연 데이터에 포함되지 않은 상황에서의 성능이 저하될 수 있는 가능성이 있다. 반면에 역강화학습은 전문가 시연 데이터를 통해 최적의 내재적 보상함수를 먼저 도출하고, 이를 통해 정책네트워크를 학습하기 때문에, 비교적 적은 전문가 시연 데이터로 강건한 성능을 확보하는 것이 가능하다(Bhattacharyya et al., 2020).
역강화방식 중 GAIL은 최적화 과정에 적대적 접근 방식을 사용하여 표본 효율성을 보다 향상시키는 알고리즘이다(Ho and Ermon, 2016). GAIL은 전문가 시연과 에이전트의 상태-행동 쌍 분포를 일치시키는 방향으로 정책을 학습시킨다. 이 과정에서 정책은 전문가 행동을 모사하는 생성기로, 내재적 보상은 에이전트의 행동과 전문가의 행동을 구별하는 판별기로 작동한다.
GAIL을 포함하는 역강화학습 방식은 전문가 시연 데이터가 최적의 보상을 받을 수 있는 행동이라는 가정을 내포하고 있다. 하지만 현실 세계에서는 전문가 시연 데이터가 최적 보상을 보장하지 못할 가능성이 있기 때문에, 위와 같은 가정은 학습과정이 지역해로 수렴할 가능성이 있다. 따라서 전문가 시연 데이터로 획득하는 내적 보상에 대한 의존성이 학습 성능 및 표본 효율성에 영향을 미칠 수 있다. 따라서 본 연구에서는 GAIL 적용에 있어 내적 보상에 대한 의존 강도가 학습성능에 미치는 영향에 대해서 분석한다.
3. DRL 모형 개발
3.1 가상물리환경에서의 크레인 및 작업 정의
크레인 주요 구조부의 물리적 동작과 작업 레이아웃에 관계된 주요 변수는 Fig. 1에서 볼 수 있다.
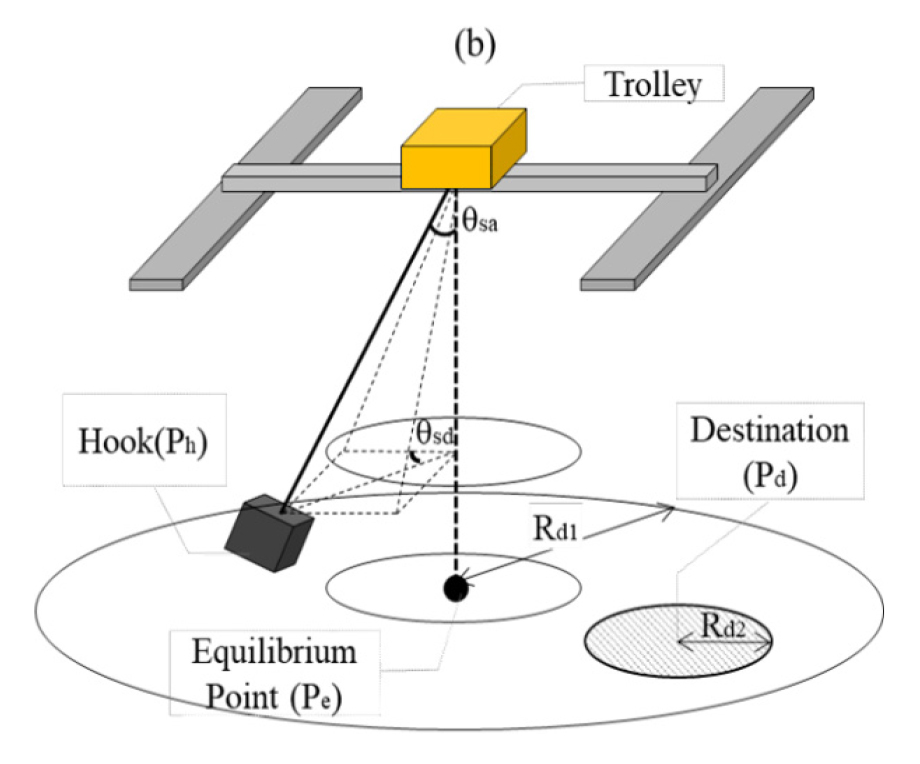
갠트리 크레인의 동작은 갠트리 프레임의 이동 및 거더 위 트롤리 이동으로 구성된다. 후크는 와이어 로프를 통해 트롤리와 연결되어 단일 진자 운동을 하게된다. 단일 진자 운동 구현을 위해 와이어 로프를 접합 거리 제약을 기반으로 구현하였다. 로프는 작은 세그먼트로 구성되며, 각 세그먼트를 접합부로 연결하여 탑재하중의 물리적 진자운동을 구현한다.
흔들림 제어를 위한 작업 정의는 다음과 같이 하였다. 평형점(Pe)은 작업 장 범위 내에서, 목적지(Pd)는 평형점(Pe)을 중심으로 하는 원환면 내에서 임의로 정해진다. 흔들림 각도(θsa)는 15° 이내 임의 값, 흔들림 방향(θsd)은 모든 방향 중 정해진다. 이와 같이 작업 레이아웃 변수를 임의로 할당하여 다양한 작업 시나리오가 생성가능한 가상물리환경을 구축하였다.
이 가상환경에서 에이전트는 다음과 같은 목표를 갖고 크레인을 제어한다: 1) 후크(hook)를 목적지(Pd)에 도달, 2) 탑재하중 흔들림을 제거, 3) 작업 시간을 최소화한다.
3.2 상태 공간 및 보상함수
상태 공간(State space)은 에이전트와 환경의 특성을 나타내는 값의 집합이다. 본 연구에서 상태 공간은 Table 1과 같이 위치 정보와 탑재하중 정보로 구성된다. 위치 정보로는 목적지(Pd) 및 후크의 위치(Ph)와 평형점(Pe) 간의 상대 좌표를 사용했으며, 흔들림 정보는 흔들림 방향(θsd), 흔들림 각도(θsa)로 구성된다. 작업 진행도 및 진자운동 궤적을 담기 위해 이상의 정보들을 10 타임 스텝 동안 누적하여 상태 공간으로 구성한다.
보상 함수(Reward function)는 에이전트가 결정한 행동에 대해 환경으로부터 받는 피드백으로 최적의 보상을 찾는데 이용된다. 앞서 정의한 작업 시나리오에서 보상은 Table 1과 같이 정의된다.
Table 1.
State space and reward function
에이전트는 흔들림 제어 작업의 목표를 달성하기 위해 후크(Ph)는 목적지(Pd)로부터 거리 임계값(Rd2) 이내에 위치시켜야 하며, 단일 진자의 기계적 에너지(Etot)도 특정 임계값(Eth)보다 낮아야 한다. 기계적 에너지는 다음 수식과 같이 구해진다.
(m: 탑재하중의 중량, g: 중력가속도, l: 로프 길이)
한편, 후크와 목적지사이의 거리가 일정 거리(Rd1) 이상 멀어지는 경우 작업에 실패한 것으로 간주한다. 이와 같은 작업 조건을 만족하는 경우 에피소드가 종료되며, Table 1과 같이 에이전트에게 희소한 보상(sparse reward)이 주어진다.
그러나 희소한 보상을 얻는데 무한한 탐색이 필요할 수 있으므로 희소한 보상만으로는 성공적인 정책 교육이 어렵다. 따라서 본 연구에서는 에이전트가 목적지에 도달하고, Rd2 이내의 반경에 머물 수 있도록 밀집 보상(dense reward)을 다음과 같이 부여한다. 후크(Ph)와 목적지(Pd) 사이의 거리가 Rd2보다 작을 때 작은 보상이 주어지며, 이후 다시 거리가 Rd2 이상 멀어지면 보상을 잃게 된다.
또한, 작업 시간을 단축시키기 위해 음의 보상이 매 타임 스텝마다 작은 크기로 주어진다. 에이전트의 무한한 탐색을 방지하기 위해 한 작업 에피소드의 최대 타임 스텝(max step)은 1,000으로 설정했다.
3.3 정책 네트워크
크레인 에이전트의 흔들림 제어 정책은 환경에서 관찰한 데이터를 기반으로 행동을 선택하도록 훈련된다. 이 정책은 신경망으로 표현되며, 256개의 노드를 가지는 2개의 레이어에 누적된 상태 공간을 처리하기 위한 순환 레이어를 추가하여 구성한다. 이 정책 네트워크는 근위 정책 최적화(PPO) 알고리즘으로 최적화된다(Schulman et al., 2017).
4. 실 험
4.1 실험 설정
실험은 PPO와 GAIL를 활용한 표본 효율성의 개선효과 검증과 GAIL의 내적 보상 의존 강도에 따른 표본 효율성과 학습성능에의 영향을 확인하기 위해 수행되었다.
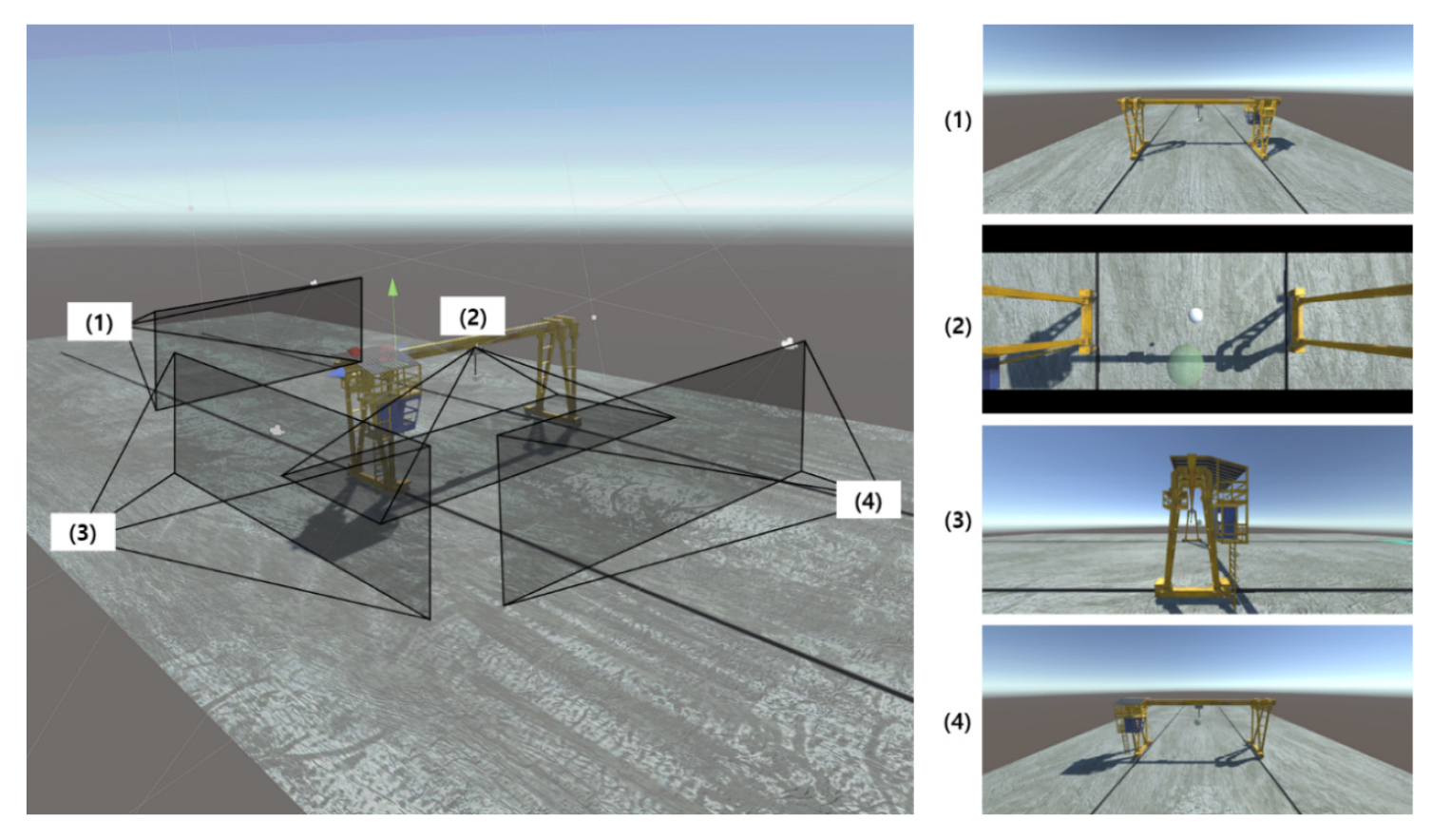
전문가 시연 데이터는 전문가에게 Fig. 2와 같은 환경을 제공하여 90개의 에피소드에서 약 50,000 스텝 동안 수집됐다. 표본 효율성 측면에서의 GAIL의 효과와 내적 보상 의존 강도의 영향도를 확인하기 위해, 순수 PPO를 활용한 모형과 GAIL의 내적 보상 강도의 가중치를 0.25, 0.5, 0.75, 1.0로 변화시킨 4가지 모형에 대해서 실험을 수행하였다.
4.2 결과 및 논의
Fig. 3은 각 모형의 학습과정 중, 에피소드 별 누적보상 값과 에피소드의 길이(time step 수)의 변화를 상자그림의 형태로 보여준다. 먼저 PPO만으로 구성된 강화학습 모형(Default)은 GAIL이 추가된 다른 모형과 비교하여 모든 시간 영역에서 낮은 누적 보상 값을 보여준다. 또한 에피소드 길이의 경우 Default 모형의 값이 다른 값보다 낮게 수렴하는 것을 볼 수 있는데, 이것은, 작업공간 이탈로 인한 에피소드 조기 종료로 인해 작업의 실패하는 경우가 많아서 줄어드는 것으로 나타났다. 결과적으로 GAIL 적용을 통한 표본 효율성 개선 효과가 있는 것으로 확인되었다.
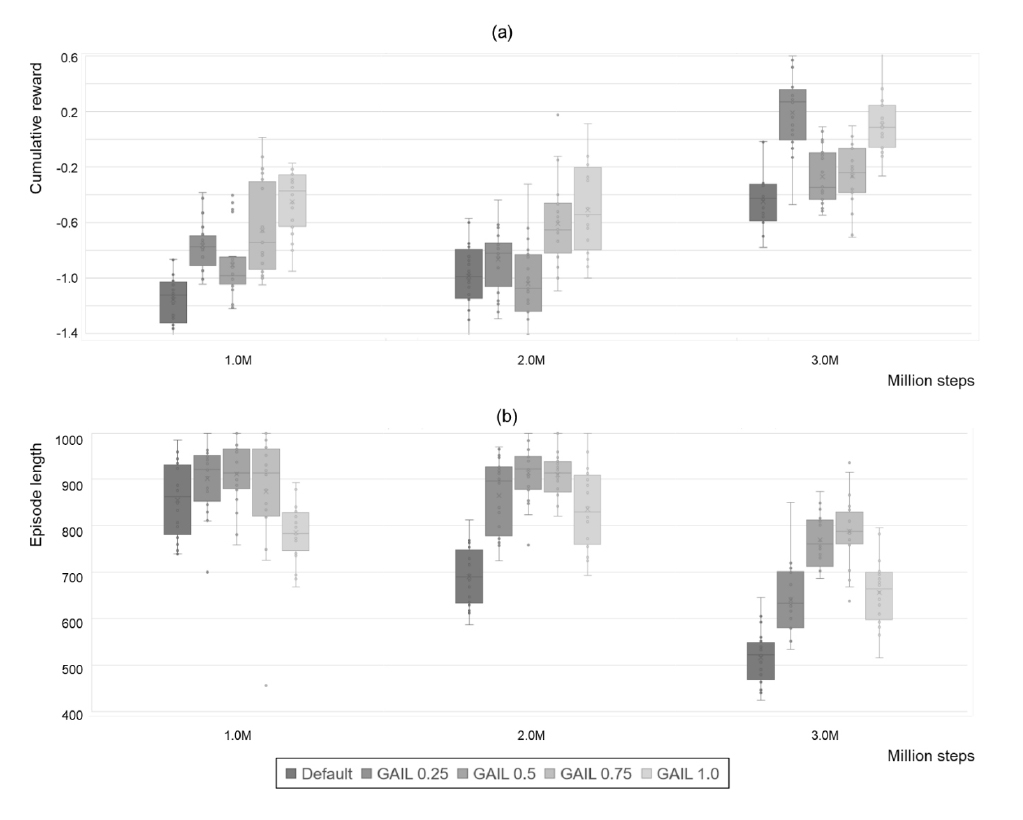
하지만 전문가 시연 데이터에 대한 의존도가 표본 효율성에 미치는 영향은 학습 시간에 따라 다른 양상을 보여주었다. 먼저 1~2M 타임 스텝인 학습 초기에는 내적보상에 대한 의존도가 1.0인 GAIL 1.0 모형이 안정적이고 높은 성능을 보여주고 있지만, 3M 시간 스텝인 학습 후반에서는 획득한 보상 및 에피소드 길이 측면에서 GAIL 0.25 및 GAIL 0.5 모형의 성능이 크게 향상되는 것으로 나타났다. 이것은 전문가 시연 데이터가 학습초기에는 표본 효율성 개선에 크게 도움이 되지만, 최적 보상의 가정을 보장할 수 없는 경우에 외적 보상을 통한 학습을 방해하여 더 높은 성능을 달성할 수 없기 때문이라고 추론할 수 있다.
5. 결 론
본 연구는 크레인의 흔들림 제어작업을 대상으로 DRL 모형의 제어 정책 학습 시 발생하는 표본 효율성 문제를 개선하는 학습 기법에 대해서 실험을 통해 고찰하였다. 실험결과를 통해 전문가 시연 데이터를 사용하는 GAIL이 에이전트가 크레인을 제어한 정책을 학습하는데 있어 속도와 성능 측면에서 유의미한 효과를 보여주는 것으로 확인되었다. 하지만 전문가 시연 데이터에 대한 강한 의존도는 오히려 표본 효율성이 저하시키는 결과를 보여주었다. 따라서 크레인 자율화 기술을 위한 GAIL 적용에 있어 전문가 시연 데이터 의존도에 대한 분석이 필수적이다.
본 연구의 한계와 향후 연구에 대한 논의는 다음과 같다. 제안된 접근 방식은 갠트리 크레인과 운영 체제가 유사한 오버헤드 크레인 및 브리지 크레인에는 매우 효과적일 것으로 기대된다. 반면, 선회 동작을 하는 회전식 크레인에는 그 효과가 제한적일 것으로 예상된다. 본 연구에서는 크레인의 환경적 상태 변화(로프 길이 및 움직임 속도)를 제한하여 크레인 모형의 동작 선택에 영향을 미치는 상태와 환경을 단순화했다. 향후 연구에서는 다양한 종류의 상태에서의 크레인 제어 정책이 개발되어야 한다.
