

1. 서 론
1.1 연구의 배경 및 목적
1.1.1 연구의 배경
최근 중대재해처벌법을 비롯한 각종 건설안전 관련 규제가 강화되었다. 이러한 배경에서 많은 건설업체들이 업체 규모에 상관없이 안전관리자 확보에 주력하고 있다. 그러나, 건설현장 안전관리에 전문성을 갖춘 인력은 턱없이 부족한 상황이며, 이러한 수요-공급 불균형으로 인해 많은 건설업체가 안전관리자 확보에 어려움을 겪고 있다. 건설현장 엔지니어 및 관리자들이 지니고 있는 작업안전에 대한 지식이 제한적인 것 또한 현장에서 이루어지는 건설안전관리의 효과성을 저해하고 있다.
미국, 영국, 호주 등 이전부터 건설안전관리에 적극적인 관심을 보였던 국가들에서는 건설현장과 같은 위험작업환경의 안전성 제고를 위해 작업(Job)단위로 위험(Hazards)과 위험저감방법(Risk Reduction Measures)을 분석하여 문서화시키는 작업안전분석(Job Safety Analysis, JSA)을 의무화하고 있다. 한국에서도 한국산업안전보건공단(KOSHA)이 2013과 2020년에 작업안전분석에 대한 기술지침을 공표하였다(안전보건공단, 2020). 이 지침에 따르면, 작업안전분석을 통해 각 단계별 작업수행과정에서 발생할 수 있는 위험 및 리스크를 파악하고, 해당작업을 안전하게 수행하기 위한 작업 방법 및 위험저감대책을 작업 전에 반드시 마련해야한다.
건설작업안전을 위한 표준적인 기술 및 방법에 대하여 각국 정부 산하 안전관리를 주관하는 부처에서 ‘지침(Guide 또는 Guideline)’ 이라 불리는 형태의 문서를 작성하여 공표하는 것이 일반적이다. 이것은 건설업체들마다 각기 다른 안전관리 방법을 사용하는 것이 아니라, 권위있는 안전관리기법이 다양한 현장에 걸쳐서 일관되게 사용되도록 만들려는 정부의 노력이라 볼 수 있다. 예를 들어, 호주의 경우에는 Safe Work Australia 라는 연방정부 산하 기관에서 Codes of Practice 라고 하는 문서를 다양한 공종별로 공표하고 안전관리 기법의 표준과 기준을 제시한다. 한국의 경우에는, 안전보건공단에서 ‘안전보건작업지침’, 영어로는 KOSHA GUIDE 를 제·개정하고 KOSHA 웹사이트에 공표하고 있다. 본 논문의 작성시점인 2022년 12월 기준 104개의 건설작업안전 관련 기술지침이 공표되어 있다. 이러한 작업안전 기술지침의 예로는 ‘사장교 교량공사 안전보건작업 지침’, ‘경량철골 천장공사 안전보건작업 지침’, ‘단순 슬래브 콘크리트 타설 안전보건작업 지침’ 등이 있다.
여기서 문제는 이러한 안전관리지침등이 모두 분절된 PDF 문서로 존재하고 있어, 관련된 지침 내용의 상호관련성 파악이 어렵고, 실무에 사용이 매우 불편하다는 점이다. 하나의 지침 문서는 그 양이 수십페이지에 이르기 때문에 100개가 넘는 건설관련 안전관리 기술지침의 총 페이지 수는 수천 페이지에 이르며, 이러한 방대한 지식을 전부 숙지하기는 매우 어려운 일이다.
1.1.2 연구의 목적
이러한 배경에서 본 연구의 목표는 자연어처리 기술을 이용해 텍스트 형태로 존재하는 건설안전관리 지침의 내용을 지식그래프(Knowledge Graph)로 변환하는 워크플로우 모델을 개발하는 것이다. 방대한 텍스트 데이터를 지식그래프로 전환하는데 있어 가장 중요한 요소는 자동화라 볼 수 있다. 수천 페이지에 이르는 건설관리지침을 수동으로 지식그래프 형태의 DB로 만드는 것은 비용과 시간측면에서 매우 비효율적이기 때문이다. 본 연구에서는 지식그래프 생성 자동화의 요소기술로서 자연어처리 기반 키워드 추출 기술과 키워드들을 기반으로 안전지침의 내용을 상호 연계하는 지식그래프 자동생성 기술을 제안한다.
본 논문의 이후 내용 구성은 다음과 같다. 본론에서는 관련된 이전 연구에 대한 문헌검토로 시작하여, 제안하는 지식그래프 생성 워크플로우의 개요를 설명하며, 사례를 통해 제안된 워크플로우의 효과성을 검증한다. 이후 결론에서는 연구의 의의 및 한계점을 설명한다.
2. 본 론
2.1 문헌 조사
2.1.1 온톨로지 기반 건설안전 데이터베이스 연구
2000년대 이후 온톨로지(Ontology) 기반 인공지능 기술을 이용해 건설작업 위험 및 안전관리기법에 대한 지식을 체계적으로 DB화 시키려는 연구가 이루어졌다(Table 1).
Table 1.
Previous studies on ontology modeling of construction safety knowledge (a. automation of knowledge base creation, b. automation of hazard identification, c. ontology-based safety risk assessment, d. automation of accident case retrieval, e. automation of hazardous spots, f. automation of job safety analysis)
| 저자 | a | b | c | d | e | f | |
| 1 | Xiong et al.(2019) | - | ∨ | - | - | - | - |
| 2 | Zhong et al.(2015) | - | ∨ | - | - | - | - |
| 3 | Kim et al.(2016a) | - | ∨ | - | |||
| 4 | Rahman et al.(2018) | - | - | ∨ | - | - | |
| 5 | Kim et al.(2016b) | - | - | - | - | ∨ | - |
| 6 | Goh and Chua(2009, 2010) | - | - | - | ∨ | - | - |
| 7 | Lu et al.(2015) | - | ∨ | - | - | - | - |
| 8 | Kim et al.(2013) | - | - | - | ∨ | - | - |
| 9 | Wang and Boukamp(2011) | - | - | - | - | - | ∨ |
| 10 | Zhang, S, Boukamp and Teizer (2015) | - | - | - | - | - | ∨ |
| 11 | Chi, Lin and Hsieh(2014) | - | - | - | - | - | ∨ |
2.1.2 지식격차 및 연구 범위
Table 1에 언급한 기존 연구들은 주로 건설안전작업 분석 및 위험물/리스크 식별을 컴퓨터 기반으로 자동화하려는 목적으로 수행된 연구로서, 주로 건설안전이라는 주제영역의 온톨로지 스키마를 개발하는데 중점을 두고 연구가 수행되었다. 그러나, 이러한 기존 연구들은 공통적으로 그래프 DB를 자동으로 구축하여 효율적으로 지식베이스를 생성해내는 방법에 대해서는 한계점을 보였다. 다른 말로, 지식베이스의 구조 또는 뼈대라 볼 수 있는 스키마(Schema)에 대한 연구는 많이 이루어 졌으나, 지식베이스의 내용에 해당하는 지식정보를 어떻게 수집하고 수집된 정보를 어떻게 효율적으로 DB화 시킬지에 대한 연구는 부족했다고 볼 수 있다.
본 연구는 이와 같은 지식격차(Knowledge Gap)를 겨냥해, 자연어처리를 통한 지식그래프 DB생성의 자동화에 초점을 맞추고 수행되었다. 특히, 건설안전 관리자가 쉽고 편리하게 질의를 통해 통합된 지식DB에서 관련된 작업안전지침 사항들을 한번에 조회할 수 있도록 하는 지식검색기능을 주된 사용목적으로 하는 DB 시스템을 염두에 두고 지식그래프 DB의 생성 방법을 제안한다.
2.2 건설안전지침 지식그래프 생성 워크플로우 모델 제안
Fig. 1은 본 연구에서 제안하는 건설작업안전지침 지식 DB 생성을 위한 워크플로우를 보여준다. 국가건설기준용어집, 사고사례데이터, 건설작업안전지침, 안전관리계획서, 유해위험방지계획서 등 건설안전관리에 관련된 문서화된 소스를 출발점으로 하여, (1)문서 전처리 및 (2)키워드추출을 거쳐 건설안전지침 텍스트데이터의 범주(category)-내용(content)-키워드(keyword) 리스트를 담고 있는 테이블데이터를 생성하고, 이 데이터를 지식그래프 DB로 변환하는 (3)지식그래프 변환 과정을 포함하는 워크플로우로 제안된다. 아래는 각 단계에 대한 구체적인 제안사항이다.
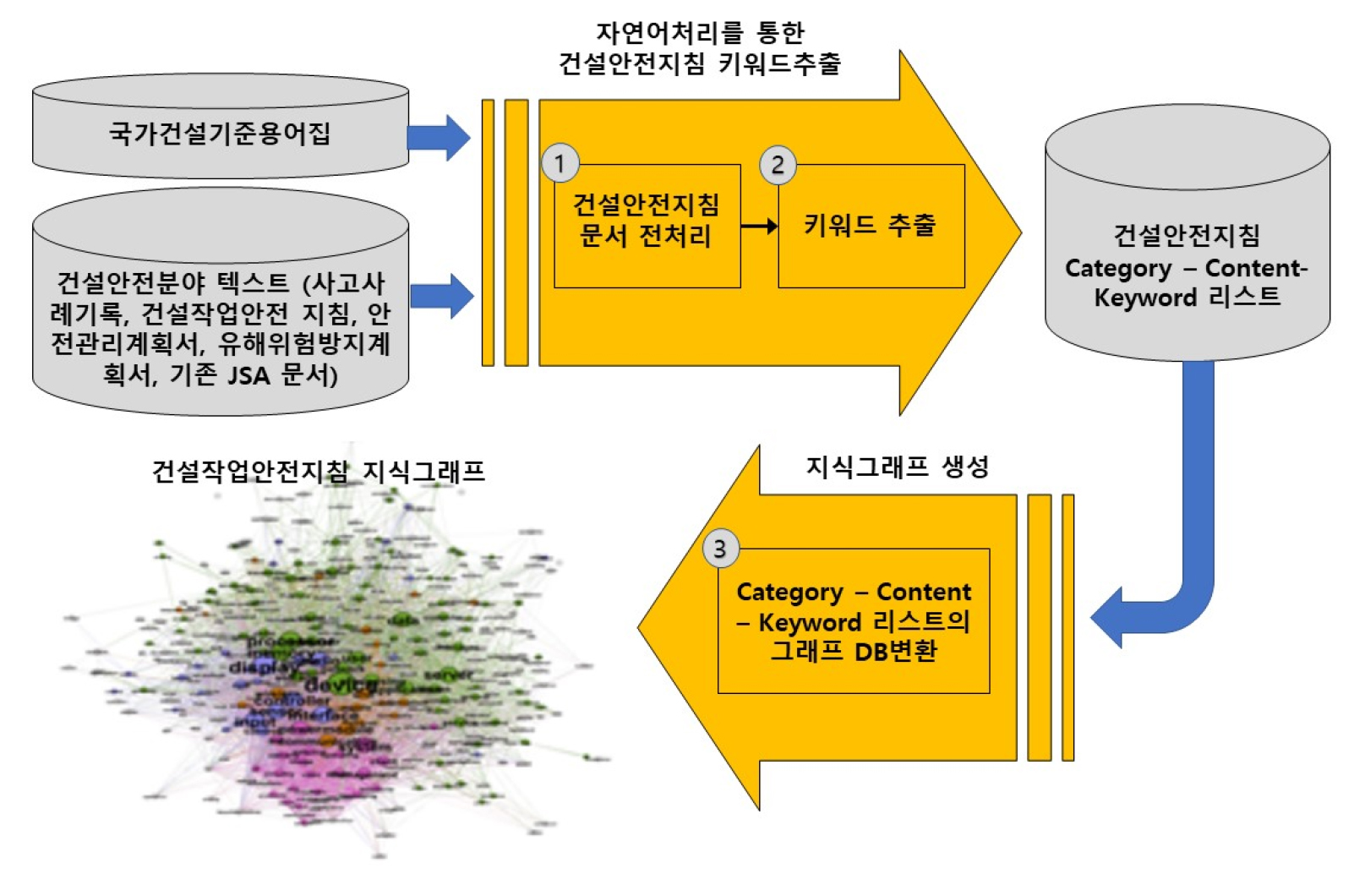
2.2.1 데이터 전처리
본 연구는 건설안전지침 내에 담긴 내용을 ‘포함(include)’의 관계를 중심으로 계층적으로 그래프 DB화 시키는 방법을 제안한다. 따라서, 건설안전지침내 각 지침 내용을 content로 나타내고, content를 주제별로 묶은 소제목을 의미하는 category내 부분집합의 개념으로 지식그래프화 할 것을 제안한다. 이를 위해, 건설안전관리 지침 PDF 문서들은 데이터 전처리 코드를 이용해 content 및 category 와 같은 필드를 갖고 있는 테이블 형태의 텍스트데이터로 미리 변환될 필요가 있다.
2.2.2 키워드(keyword) 추출
다양한 자연어처리 알고리즘(예: TF-IDF, Google BERT)를 통해 각 content 항목으로부터 keyword가 추출될 수 있다. 자연어처리 키워드 추출기법은 일반적으로 각 토큰에 단어의 빈도와 역 문서 빈도를 이용해 각 단어의 중요성을 가중치로 준다(Wang et al., 2010). 특히, TF-IDF 가중치 모델은 모든 문서에서 자주 사용되는 단어는 불용어와 같은 단어로 판단하여 중요성에 대해 낮은 가중치를 주고 특정한 문서에서만 자주 등장하는 단어의 중요성에 높은 가중치를 주기 때문에(Yoo et al., 2022) 문장단위의 content로부터 효과적으로 keyword를 추출하는데 사용될 수 있다.
2.2.3 지식그래프 모델링
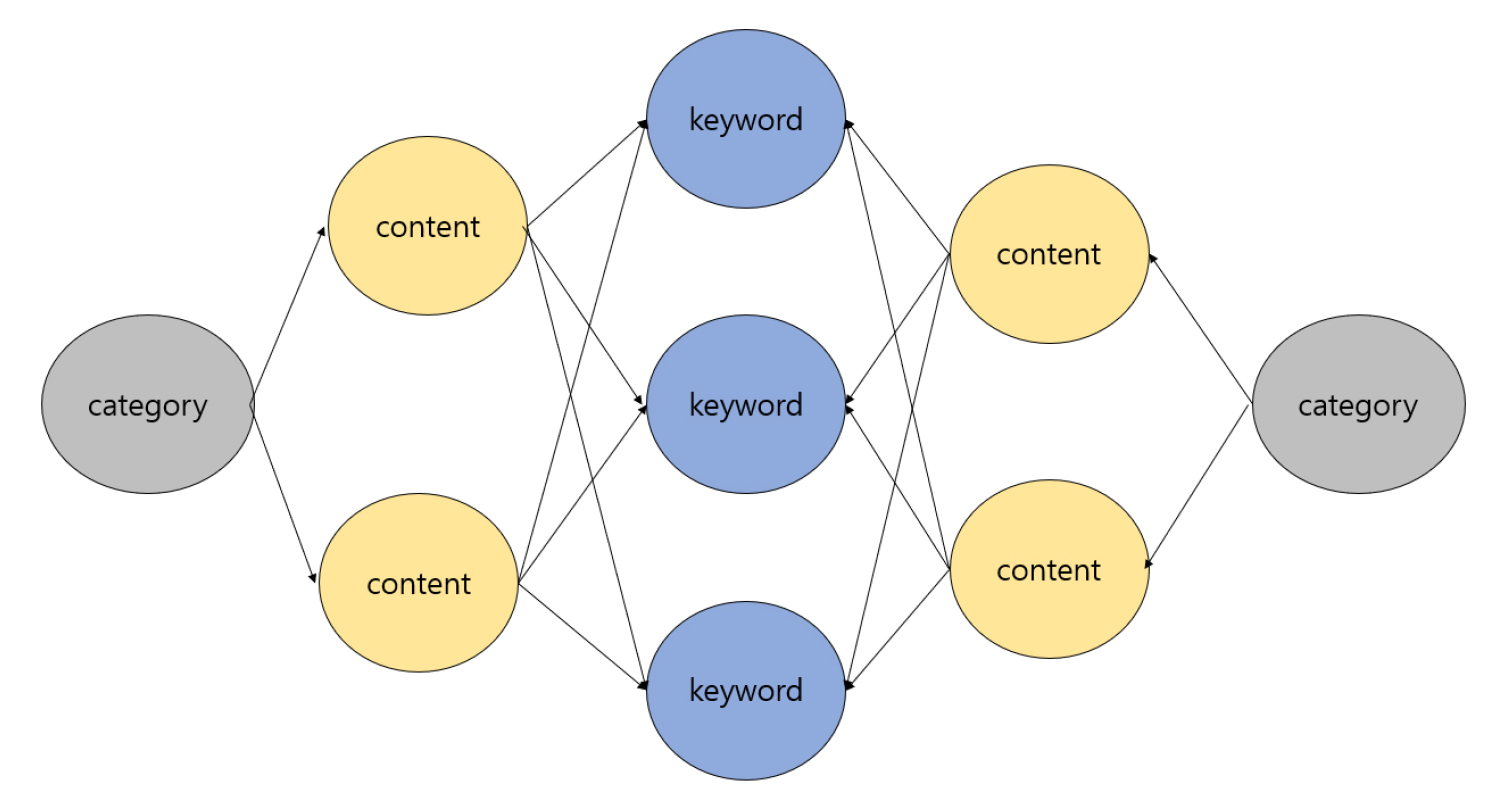
지식그래프의 구조는 집합관계를 이용하여 표현한다. category 노드가 content 노드를 ‘포함’하는 관계로 정의되고 content 노드가 keyword노드를 ‘포함’하는 관계로 정의된다. content노드의 속성(Property)으로는 title(데이터 출처 문서명) 과 keyword 리스트가 정의된다(Fig. 2).
2.3 사례 연구
2.3.1 데이터 전처리
한국산업안전보건공단의 KOSHA Guide 중 ‘건설안전지침’를 활용하여 데이터베이스를 구축하였다. (안전보건공단, KOSHA Guide 중 건설안전지침, https://www.kosha.or.kr/kosha/data/guidanceC.do). Fig. 3는 예시로서 <현수교 교량공사 안전작업 보건 지침>의 일부를 보여준다.

이러한 지침문서의 제목을 title로 설정하고, 지침내의 소제목을 category로 설정하였다. 또한, 소제목내의 각각의 항목을 content로 구성하여 데이터 전처리 과정을 진행하였다. 결과적으로 총 28개의 지침에 포함된 1834개의 content를 CSV(Comma Separated Values) 데이터 형태로 저장하였다. Table 2는 그러한 테이블 데이터의 예시를 보여준다.
Table 2.
Example of Title-Category-Content data
2.3.2 키워드 추출
본 연구에서는 한국어 형태소 분석기 KoNLPy(Korean Natural Language Processing in Python)를 통해 토큰화를 진행하였다. KoNLPy패키지에는 Hannanum, Kkma, Komoran, OKt 등 과 같은 형태소 분석기가 있다(Park and Cho, 2014). 형태소 분석기중 Okt을 통해 content 열에 포함된 텍스트 데이터의 형태소를 분류하고 그 중 명사만 추출하여 토큰화를 진행하였다.
Python은 Scikit-Learn 라이브러리를 통해 Tfidvectorizer 함수를 제공한다. Tfidvectorizer 기능은 단어의 최소 빈도수제한 (min_df), 최대 빈도수제한(max_df)과 n_gram을 통해 토큰화된 토큰의 묶음의 범위를 설정할 수 있다(Garreta and Moncecchi, 2013). TF-IDF 토큰화 과정에서 각 토큰은 BOW(Bag of Words)방식을 이용하여 추출한다. BOW방식은 각 토큰의 순서를 고려하지 않고 단어 집합 토큰의 빈도수에 집중하는 방식이다(Zhang et al., 2010). n_gram을 지정함에 있어 순서를 고려하지 않고 각 묶음의 빈도수를 중요도 선정에 반영하여 각 토큰에 가중치를 준다.
전처리 과정을 통해 생성된 CSV 파일을 이용하여 keyword 추출을 진행하였다. KoNLPy를 이용하여 content 항목을 Okt 형태소 분석기를 통해 명사추출을 진행하였다. 다른 형태소 분석기에 비해 Okt형태소 분석기가 합리적인 속도를 가졌고 띄어쓰기, 오탈자가 있는 경우에 높은 성능을 보이기에 Okt형태소 분석기가 사용되었다. 또한, keyword 추출을 위해 TF-IDF함수가 사용되었다. 건설안전지침에 구 단위의 단어가 많이 사용되고 이 단어가 유의미한 경우가 많기 때문에 단어의 묶음(n_gram)은 1개 ~ 3개로 설정되었다. 최대 빈도수(max_df)는 50개로 설정되어 너무 많이 반복되는 단어는 제거되었다. 이러한 성정 값을 바탕으로, 가중치가 높게 계산된 토큰이 각 content의 keyword로 추출되었다. Fig. 4는 이러한 인수값 설정을 통해 각 content로부터 keyword를 추출하는 Python 코드를 보여준다. 이렇게 생성된 keyword 들은 CSV파일에 추가된 ‘keywords’ 필드에 배열의 형태로 저장되었다(Table 3).

Table 3.
Example of keywords extracted through TF-IDF method
2.3.3 지식그래프 모델링
본 연구에서는 Neo4j를 플랫폼으로 이용하여 지식그래프를 구축하였다. Neo4j는 그래프 데이터 베이스(Graph Database) 질의 언어(Query Language)로 사이퍼(Cypher)를 이용하는 지식 그래프 플랫폼(Knowledge Graph Platform)이다(Miller, 2013).
Python 환경에서 Neo4j 라이브러리를 통해 지식 그래프를 생성할 수 있다. category는 content와 include 관계(link)로 연결되고, 마찬가지로 content는 keyword와 include 관계로 연결된다. 또한, content의 특성(Property)은 title, category, content, keyword로 구성 되었다. Fig. 5는 범주(category)-내용(content)-키워드(keyword) 리스트를 담고 있는 테이블데이터로부터 노드(node)와 링크(link)들이 자동으로 생성되도록 하는 Python 코드를 보여준다.

이러한 프로그램을 통해, 최종적으로 28개의 안전관리기술지침 문서의 내용이 51,000개의 node, 95,000개의 link로 구성되었다(Fig. 6). (51000 개의 node는 단어 묶음(n_gram)지정을 통해 구 단위 추출이 이루어져 node수가 명사의 수보다 15.46배 정도 증가하였음을 암시한다.)
2.4 지식그래프 질의응답 성능평가
2.4.1 지식그래프 성능평가를 위한 질의목록
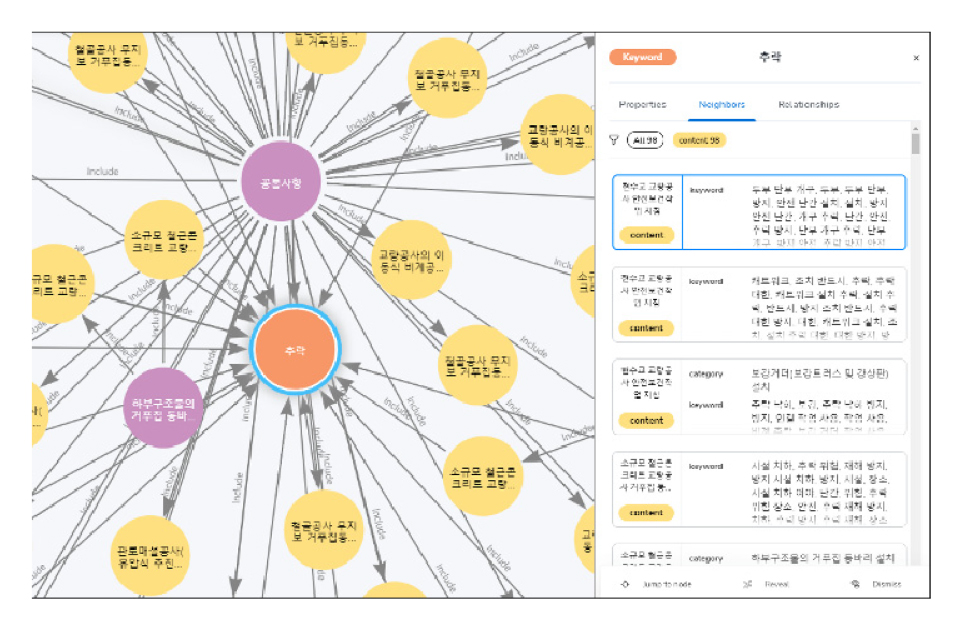
이렇게 생성된 지식그래프의 지식검색 성능평가를 위해, Neo4j 지식 그래프 플랫폼 내 Bloom 이라는 소프트웨어가 사용되었다. 이 소프트웨어 환경내에서 필터 기능을 사용하여 원하는 검색어가 포함되어 있는 지침항목의 세무 내용과 목록을 확인할 수 있다. Fig. 7은 “추락”이라는 키워드를 포함하고 있는 지침내용 목록을 검색한 Neo4j Bloom 화면이다.
키워드로 검색하였을 때 그러한 키워드를 포함하고 있는 지침 내용을 반환할 수 있는지 확인하는 ‘단순질의’와 지정된 건설안전지침 문서 내에서 원하는 검색어에 대한 지침내용을 반환할 수 있는지 확인하는 ‘조건질의’로 질문지를 구성하였다. 단순질의를 통해 정보손실 없이 TF-IDF 방식을 사용해 검색어에 사용될 수 있는 키워드가 모두 추출되었는지 알아보고자 하였고, 조건질의를 통해 원하는 조건이 추가된 상황에도 검색 정확도가 유지되는지 확인하고자 하였다.
질문지는 단순 질의 15개 조건 질의 15개로 구성하였다. 질의는 단어 단위의 검색과 더불어 구 단위의 검색을 위해 10개의 단어 단위 검색어와 5개의 구 단위 검색어로 구성하였다.
단순질의와 조건질의에 사용된 검색어의 목록은 서로 같고 각각의 검색어에 조건질의를 수행하며 특정한 건설안전지침의 제목은 Table 4에 나열되었다.
Table 4.
List of query keywords
2.4.2 지식그래프 성능평가 결과
지식검색의 정확도는 지식그래프에서 수행한 각 질의의 정답 반환 개수를 실제 건설 안전 지침 문서에서 찾은 정답의 개수로 나누어 계산하였다. 10개의 단어 단위 검색어와 5개의 구 단위 검색어로 단순질의를 수행한 결과는 Table 5에서 보이는 것과 같이 건설안전지침의 해당 항목 1017개 중 989개를 지식 그래프에서 반환하였다. 단어 단위 검색어를 통한 검색과, 구 단위 검색어를 통한 검색 모두 지식그래프 상에서 대부분의 건설안전지침 항목을 도출하였다.
단순 질의와 같은 검색어를 지정된 지침문서에서만 찾아내는 조건질의를 수행한 결과는 Table 6에서 보이는 것과 같이 건설안전지침의 해당 항목 177개 중 166개를 지식 그래프에서 반환하였다. 조건 질의 역시 단어 단위 검색어를 통한 검색과, 구 단위 검색어를 통한 검색 모두 지식그래프 상에서 대부분의 건설안전지침 항목을 도출하였다. 위 과정에 따른 단순질의의 정확도는 97.25%, 조건질의의 정확도는 93.79%로 평가되었다.
3. 결 론
본 연구에서 수행된 사례 연구의 결과는 제안된 지식그래프 생성 워크플로우 모델이 건설안전지침 문서에 담긴 내용을 지식그래프 DB 형태로 효과적으로 변환하는 데 유용함을 보였다. 97.25% 및 93.79%의 질의 정확도는 지식그래프의 자연어처리 기법을 통해 주요 검색어들이 대부분 각 지침내용으로부터 keyword로서 추출되었고 지식그래프에 포함되어 DB가 구축되었음을 의미한다.
이러한 지식그래프 DB는 단순검색과 같은 질의보다도 복합질의(예: 예/아니오 질의, 선택적 일치 질의 등)에 더욱 큰 강점을 가질 것으로 예상되므로, 더욱 다양한 형태의 질의문을 개발하여 테스트 함으로써 생성된 안전관리지식 DB의 효용성을 검증할 필요가 있다.
본 연구에서 수행된 사례 연구에서는 TF-IDF기법 기반의 키워드 추출만을 이용하였으나, 향후 연구에서는 이외에도 최근에 개발된 더욱 진보된 키워드 추출 알고리즘(예: BERT)를 사용하여 지식그래프를 생성하고 그렇게 생성된 지식그래프의 질의 성능을 다른 키워드추출 기법을 기반으로 생성된 지식그래프의 성능과 정량 및 정성적으로 비교할 필요가 있다. 또한, 본 연구에 수행된 단순질의/조건질의 기반 성능평가는 지식그래프가 의도대로 생성되었음을 보여주는 검증에 그치므로, 지식그래프의 실제적 활용도에 대한 보다 정성적인 추가 검증을 위한 연구가 요구된다.
