

1. 서 론
최근 건설 분야에서 설계·시공의 효율성 및 안정성을 향상시킬 수단으로 BIM(Building information modeling)이 적극 도입되고 있다. BIM은 건물의 전 생애주기(설계, 시공, 유지관리 단계)에 걸쳐 정보를 생산하고 통합, 관리하는 기술을 말한다(Churcher, 2019). BIM에 대한 효과로는 3차원 모델을 통해 디자인을 더 잘 이해할 수 있으며, 공기 검토 및 조절이 용이하고, 합리적인 디자인 도출을 위한 분석 및 시뮬레이션이 가능하며, 설계도서 오류나 간섭으로 인한 이슈 발생이 줄어드는 점 등이 있으며, 이는 발주자 측면에서도 BIM 도입의 장점으로 인식되고 있다.
또한 BIM은 최근 건설자동화와 로보틱스 영역의 기술적 발전과 맞물려 그 적용 범위가 점차 확대되고 있는 추세이다(Kajima, 2018; Zhang et al., 2022). 예를 들어, 일본 가지마(Kajima) 건설은 ‘스마트 퓨쳐’라는 비전 아래 건설 작업의 절반은 로봇이 작업하는 것을 목표로 기술을 개발하고 있다. 이때 시공진척도를 BIM과 연계하여, 작업이 완료된 부분에 대한 BIM 객체를 선택하여 작업진도관리에 활용하거나 품질 관리 수행에 활용하고자 계획하였다. 또한 Zhang et al.(2022)은 BIM과 로봇 간의 능동적인 정보 상호작용을 위해 ‘BIMfAR’이라는 균일한 BIM 프레임워크를 제안하였다. 이때 BIM이 활성정보 관리 모드에서 자동화된 3D 인쇄 콘크리트 작업을 위한 잠재적인 보조 도구로 활용되었다.
이처럼 BIM이 여러 분야에서 적용이 되고 있지만 현재 각 분야 별로 사용하는 BIM 소프트웨어가 서로 다른 경우가 많으며(진상윤, 2020), 이러한 경우 서로 다른 소프트웨어들 간 데이터 호환성(Interoperability)에 대한 문제점이 발생할 수 있다. 이러한 문제의 해결을 위한 노력의 일환으로 마련된 것이 국제 ISO 표준 모델인 Industry Foundation Classes(IFC)이다. 이는 건설 정보를 중립적이고 개방적인 데이터 포맷으로 제공해 줌으로써, 객체 간 정보의 교환을 가능케 하는 표준 데이터 모델로 활용되고 있다(Koo et al., 2021). 그러나 IFC 자체의 데이터 구조적인 복잡성으로 인해 BIM 소프트웨어 간 데이터 교환 시 여전히 오류 및 누락이 발생하여 교환 데이터의 시멘틱 무결성(semantic integrity)이 보장 되지 않는 문제가 존재한다(Eastman et al., 2009). 여기서 시멘틱 무결성이란 개별 BIM 부재와 관련된 제반 IFC 데이터(예, Ifc 엔터티(entity), 관계 엔터티, 속성정보)가 올바로 부여된 것을 일컫는다. 시멘틱 무결성이 보장되지 않을 경우 IFC 데이터의 품질 신뢰도가 하락하며, 이는 BIM의 본래 취지를 위협하는 요인이 될 수 있다(Koo et al., 2021).
이에 IFC 데이터의 시멘틱 무결성을 검증하기 위해 일련의 추론 규칙기반과 기계학습 기반의 시멘틱 강화(semantic enrichment) 접근법이 이용되었다(Yu et al., 2021). 규칙기반 접근법은 일련의 추론적 규칙(inference rules)을 사전에 정의하고, 이들 규칙을 활용하여 시멘틱 무결성을 검증하는 방식을 의미한다(김시현, 2022). 예를 들어, Ma et al.(2017)은 시멘틱 강화를 위해 객체를 그들의 특징(feature) 및 관계(relationship)와 연관시키는 지식 기반 프로세스와 지식과 사실 간의 유사성 측정에 기반한 매칭 알고리즘을 제안하였다. 하지만 이러한 규칙 기반의 시멘틱 강화 접근법은 분류(classification)하고자 하는 객체의 기하학적 정확도에 의해 많이 좌우되고, 각각의 규칙을 수동으로 정의해야 하는 특성으로 인해 특정 부재 및 조건에만 한정적으로 적용할 수 있다는 한계를 가지고 있다.
이러한 규칙 기반 접근법의 한계를 극복하기 위해 기계학습 접근법이 도입되었다. 특히, 최근에는 인공지능 기술의 발전으로 기계학습을 활용하여 BIM 부재의 기하정보를 학습한 후 부재 식별을 자동화 하는 연구가 활발히 진행되고 있다(Romero-Jarén, 2021; Su et al., 2015). 기계학습을 사용하게 되면 BIM 내 객체의 기하학적 정보, 2차원 혹은 3차원 형상을 학습데이터로 활용하여 분류나 예측 모델을 만들 수 있다. 이러한 모델은 사전에 학습되지 않는 객체라도 분류를 할 수 있기 때문에 활용성이 높은 접근법으로 주목받고 있다.
본 연구에서는 기존의 선행되었던 기계 학습기반의 시멘틱 강화 접근법의 일환으로, IFC 데이터로부터 3D 객체를 추출하여 포인트 클라우드(point cloud) 형태로 변환한 뒤 3차원 객체 분류 알고리즘을 활용하여 해당 객체의 IFC 클래스를 인식할 수 있는지 시험하고자 한다. 이를 통해 이러한 접근법이 IFC 데이터 상 부정확한 엔터티 정보(예, 클래스)를 인식하고 올바른 정보로 업데이트시킬 수 있는 시멘틱 강화의 한 수단으로써 사용될 수 있을지 그 활용 가능성을 평가하고자 한다.
2. 기계학습 기반 시멘틱 강화 관련 연구동향
BIM 상호운용성 확보를 위해서는 IFC 변환 시 발생하는 정보 누락 및 오류 문제 해결이 필수적이다. 이는 BIM 개별 객체와 IFC 엔터티 간 데이터 매핑이 올바른지 검증하고 정확도를 높이는 시멘틱 강화를 통해 해결할 수 있다. 이를 위해 앞서 언급했듯이 기계학습 기법에 대한 연구가 활발히 진행되어 왔으며, 최근에는 데이터의 기하학적 특성을 기반으로 BIM 요소를 구별할 수 있는 딥러닝 기반의 접근법도 시도되었다. BIM- IFC 매핑과 관련된 주요 연구들은 아래와 같다(Table 1).
Table 1.
Summary of relevant literature
| 저자 | 주요 연구내용 |
| Krijnen and Tamke (2015) | BIM 모델의 기하학적 속성에 이상치 감지를 적용하고 기하학적 속성을 기반으로 평면도를 주거용 및 비주거용 건물로 분류하기 위해 신경망을 훈련 |
| Koo and Shin (2018) | 머신러닝 기법인 SVM을 활용하여 IFC 객체의 오분류 문제 접근 |
| Lomio et al. (2018) | BIM 모델에서 240개의 이미지를 생성하고 SVM과 딥러닝을 실험하여 건물 디자인의 이미지를 세 가지 범주로 분류 |
| Kim et al. (2019) | 32개 각도에서 객체의 렌더링된 2D 이미지를 사용하여 컨볼루션 신경망을 훈련하는 다중 보기 접근 방식을 적용 |
| Koo et al. (2021) | 3D 객체 분류 알고리즘인 PointNet과 MVCNN을 이용하여 사회기반시설인 도로 BIM 객체를 분류 |
| Emunds et al. (2022) | IFC 기반 기하학 분류 및 BIM의 시멘틱 강화를 위한 신경망 모델인 SpaRse-BIM 모델 제안 |
초기의 기계학습 기반 시멘틱 강화에 대한 연구는 BIM 모델의 기하학적 속성에 이상치 탐지를 적용하여 분류하는 연구들이 진행되었다. 예를 들어, Krijnen and Tamke(2015)은 공간 부피의 평균 및 분산과 같은 기하학적 속성을 기반으로 평면도를 주거용 및 비 주거용 건물로 분류하기 위해 신경망을 훈련시켰다. Koo and Shin(2018) 또한 유사한 방법을 적용하여 이상치 탐지 분석을 기반으로 오분류된 BIM 객체를 탐색하고 재분류하였다.
다양한 분야에서 딥러닝 기법에 대한 활발한 연구가 이루어지며, 이후 진행된 연구들에서는 BIM 모델 내에서 분류할 객체에 대해 이미지 데이터나 기하학적 데이터들을 직접적으로 추출하여 딥러닝 기반의 분류 알고리즘을 통해 학습시키는 경향을 보였다. 예를 들어, Lomio et al.(2018)은 빌딩의 유형을 분류하기 위해 BIM 모델에서 240개의 이미지를 형성하여 딥러닝 모델을 학습시켰으며 0.89의 분류 정확도를 달성하였다. Kim et al.(2019)는 건축 BIM 부재들을 구분하기 위해 10개의 클래스가 있는 820개의 각 객체들에 대해 32개의 각도에서 찍은 이미지들을 데이터셋으로 만들어 심층 신경망인 2D CNN을 학습시켰다. Koo et al.(2021)은 시멘틱 강화를 위해 사회기반시설 관련 구조물의 요소들(예, 지하 배수로, 옹벽, 날개벽)로 이루어진 데이터들을 PointNet과 MVCNN 알고리즘으로 학습시켜 그 성능 차이를 비교 분석하였으며, 그 결과 다중 이미지 기반의 MVCNN 모델이 분류 정확도 면에서 우세를 보였다. 이와 같이 2D 이미지 데이터를 이용하여 시멘틱 무결성을 검증하는 방법은 최근 이미지 분석 기술의 발달로 인해 정확도 면에서 전반적으로 우수한 성능을 보였던 반면, 기하학적으로 유사한 부재들에 대해서는 상대적으로 낮은 성능을 보이는 것으로 나타났다. 또한, 딥러닝 모델의 학습을 위해 많은 양의 데이터가 요구되며, 이를 학습하는데 시간이 많이 걸린다는 한계가 지적되었다. 이러한 딥러닝의 연산 시간을 줄이기 위한 노력으로 최근 Emunds et al.(2022)는 이미지 데이터를 활용하지 않고 곱셈 및 덧셈 등의 연산량을 줄여 연산속도를 향상시킨 Sparse Neural Network기반의 ‘SpaRse- BIM’ 모델을 제안하였으며, IFC 기반 BIM 모델의 기하학적 정보 분류에 대한 성능을 IFC 클래스가 라벨링된 IFCNetCore라는 데이터셋(Emunds et al., 2021)으로 검증하였다.
이전 연구들은 IFC 객체 분류를 위한 다양한 기계학습 및 딥러닝 기법들을 제안함으로써 BIM 모델의 상호운용성을 향상시키는데 기여를 하였다. 특히, 딥러닝 기법은 공간적 정보 및 패턴을 학습에 활용함으로써 BIM 객체 분류에 있어 우수한 성능을 보이는 한편, 최근 연구결과는 분류의 대상 객체에 따라 그 성능에 차이가 날 수 있음도 보여주었다. 이에 본 연구에서는 IFC 기반 시멘틱 강화 자동화의 선행 연구로써 학습 데이터(예, 객체별 데이터 분포)가 딥러닝 알고리즘의 성능에 미치는 영향을 조사하고자 한다.
3. 연구개요
본 연구는 지도학습 기반의 PointNet(Qi et al., 2017)을 활용하여 IFC 데이터로부터 추출된 3차원 포인트 클라우드 모델을 객체별로 분류하는 기법을 제시한다(Fig. 1). 지도학습은 해당 레이블이 있는 데이터셋을 사용하여 분류 알고리즘을 학습하며, 학습되지 않는 데이터의 레이블을 학습된 모델로 예측하는 방식으로 분류를 수행한다(Kotsiantis, 2007). 특히, 학습에 사용되는 데이터를 두 개의 공공 데이터셋으로부터 수집, 구축함으로써 학습 데이터가 알고리즘의 성능에 미치는 영향을 조사하고자 하며, 이 과정에서 IFC 데이터를 분류 알고리즘의 입력층에 적합한 데이터 형식으로 변환할 수 있는 전처리 기법을 도입하였다. 이러한 접근법은 IFC 데이터 상 오분류된 객체의 엔터티를 인식하고, 올바른 엔터티를 추정함으로써 향후 IFC 데이터를 업데이트하는데 기반이 되는 기술로 활용될 수 있으며, 개별 BIM 객체와 IFC 엔터티 간 데이터 매핑이 일치하도록 함으로써 BIM 소프트웨어 간 상호운용성을 향상시키는데 기여할 것으로 기대된다.
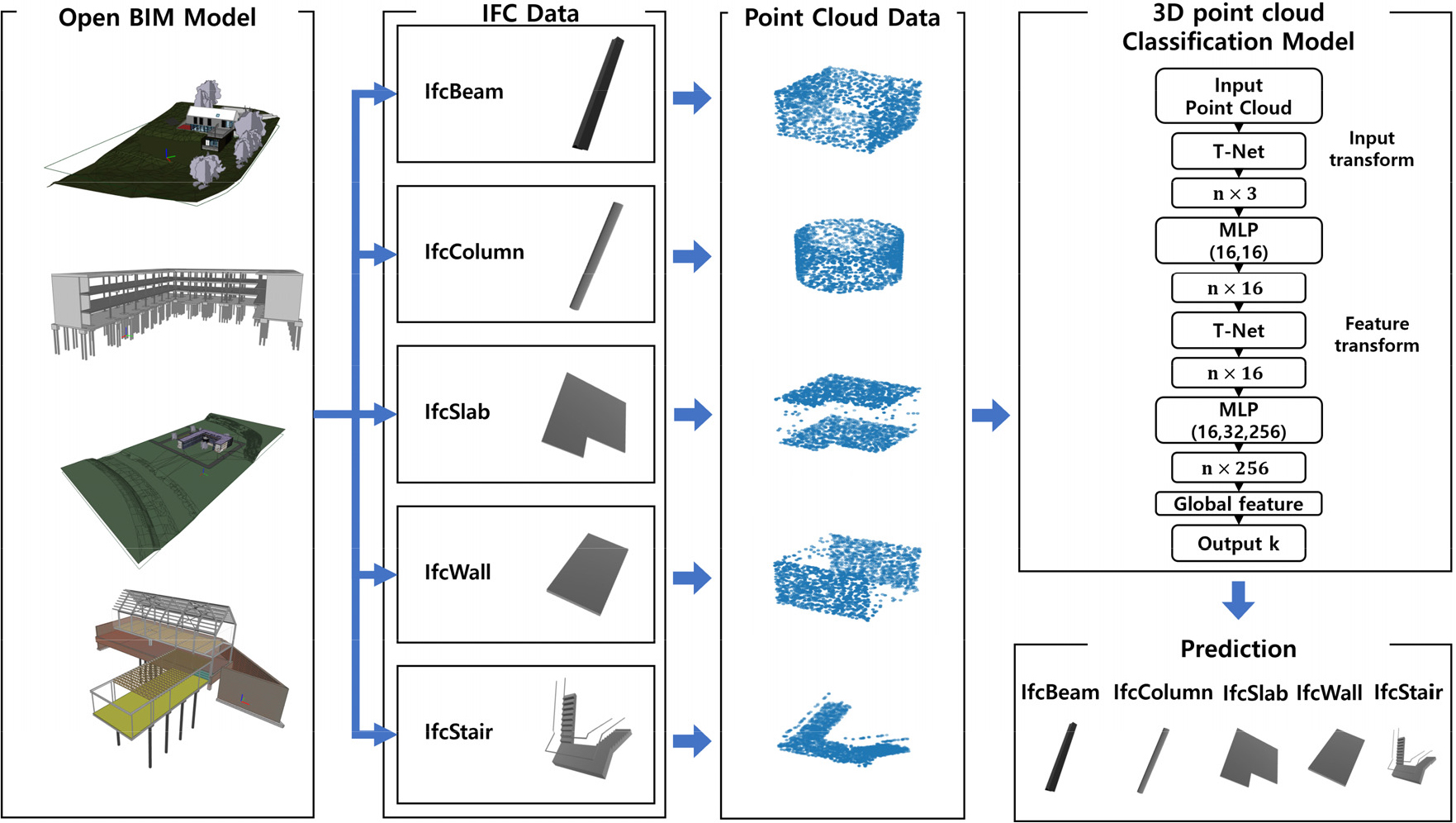
본 논문의 연구내용은 (1) 학습 데이터 구축을 위한 IFC 데이터 전처리, (2) 딥러닝 기반의 분류 알고리즘의 2단계로 구성되며, 단계별 내용은 아래와 같다.
3.1 IFC 데이터 전처리
본 연구에서 사용된 IFC 데이터셋은 Purdue University에서 제공하고 있는 ‘Building information modeling(BIM) data repository with labels’이다. 이 데이터셋은 4개의 BIM 모델에서 각각의 IFC 엔터티를 추출하여 각 엔터티들에 대한 이름(예, beam, slab)을 기록하는 라벨링 과정을 통해 제작되었다. 또한 앞서 언급한 IFCNetCore 데이터셋(Emunds et al., 2021)을 추가하여 본 연구에서 사용될 IFC 포맷 형태의 파일들을 5개의 클래스(IfcBeam, IfcColumn, IfcSlab, IfcWall, IfcStair)로 나누었다.
IFC 데이터 포맷은 그 자체로 분류 모델을 구축하는 데이터로 활용될 수 없기 때문에 분류 알고리즘에 적용하기 위해 데이터를 전처리(Preprocessing) 하는 과정이 필요하다. 전처리의 구현은 각각의 IFC 엔터티를 IfcConverter 프로그램을 통해 ifc 형태의 파일을 obj 형태로 변환하였고, python의 trimesh 라이브러리를 이용하여 포인트클라우드 형태로 변환하였다(Fig. 2). 본 연구에서는 총 1,951개의 IFC 데이터를 포인트 클라우드 데이터로 변환하였으며, 전처리 과정을 통해 일정한 품질의 데이터를 확보할 수 있었다.
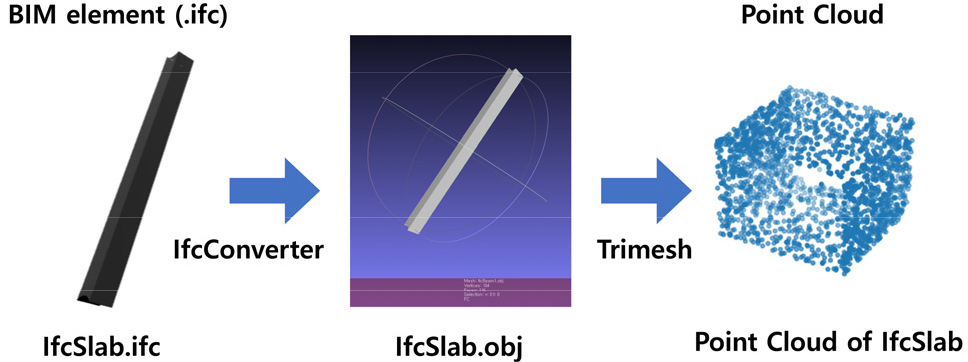
전처리를 통해 생성된 포인트 클라우드 데이터로부터 학습(training)과 평가(test) 데이터셋들을 구축하였다. 총 5개의 엔터티에 대한 데이터를 이용하여 분류 알고리즘을 학습 및 검증하였으며, 각각의 엔터티에 대한 분포는 Table 2와 같다.
Table 2.
Training and test sets for classification
| Classes |
No. of training data |
No. of test data |
No. of total data |
| IfcBeam | 375 | 214 | 589 |
| IfcColumn | 203 | 176 | 379 |
| IfcSlab | 274 | 114 | 388 |
| IfcWall | 376 | 167 | 543 |
| IfcStair | 36 | 16 | 52 |
| Total | 1264 | 687 | 1951 |
3.2 딥러닝 기반 분류 알고리즘
본 연구에서 활용된 PointNet은 3차원 객체의 형상 및 색상 정보를 나타내는 포인트 클라우드를 학습하여 3차원 객체를 분류하는 딥러닝 알고리즘(Qi et al., 2017)으로 각 BIM 객체별로 IFC 엔터티와의 데이터 매핑이 올바른지 검증하기 위해 적용하였다. PointNet 이전의 3D 객체를 분류하는 연구에서는 객체를 복셀화 또는 이미지 모음으로 변환하여 알고리즘을 학습하였다. 이러한 방법은 데이터를 불필요하게 방대하게 만들고, 연산량이 많아 학습시간이 오래 걸린다는 단점이 존재하였다. 이러한 문제를 해결하기 위해 분류 네트워크는 포인트 클라우드 자체를 학습하여 특정 개수(예, 2,048개)의 포인트들을 입력으로 받아 “T-nets” 변환행렬을 적용한 다음 최대 풀링 레이어를 통해 특징을 추출한다. 최종 muiti-layer perceptron(MLP) 계층에서는 입력데이터 클래스 갯수에 대해 각각의 분류 스코어를 출력한다.
본 연구에서는 학습의 연산속도를 최적화하기 위해 다양한 크기(예, 파라미터 수)의 네트워크를 시험하였으며, 성능 및 연산 속도를 고려하여 최종 모델(Fig. 1)을 선정하였다. 또한, 분류 네트워크의 입력데이터인 포인트 클라우드의 규모를 1,024개, 2,048개, 4,096개의 포인트 개수에 대해 비교, 분석하였으며, 포인트들을 T-net 형태의 레이어를 통해 이동 및 회전에 영향을 받지 않는 포인트의 고유 특징을 가진 특징 공간으로 변환하고, 최대 풀링레이어(Max pooling Layer)를 통해 특징을 집계한 다음 256개의 전역 특징(Global feature)들을 추출하였다. 최종(16,32,256) 형태의 MLP 계층을 통해 각 유형에 해당하는 분류 스코어를 출력하여 입력 데이터의 해당 엔터티를 예측하였다.
4. 결 과
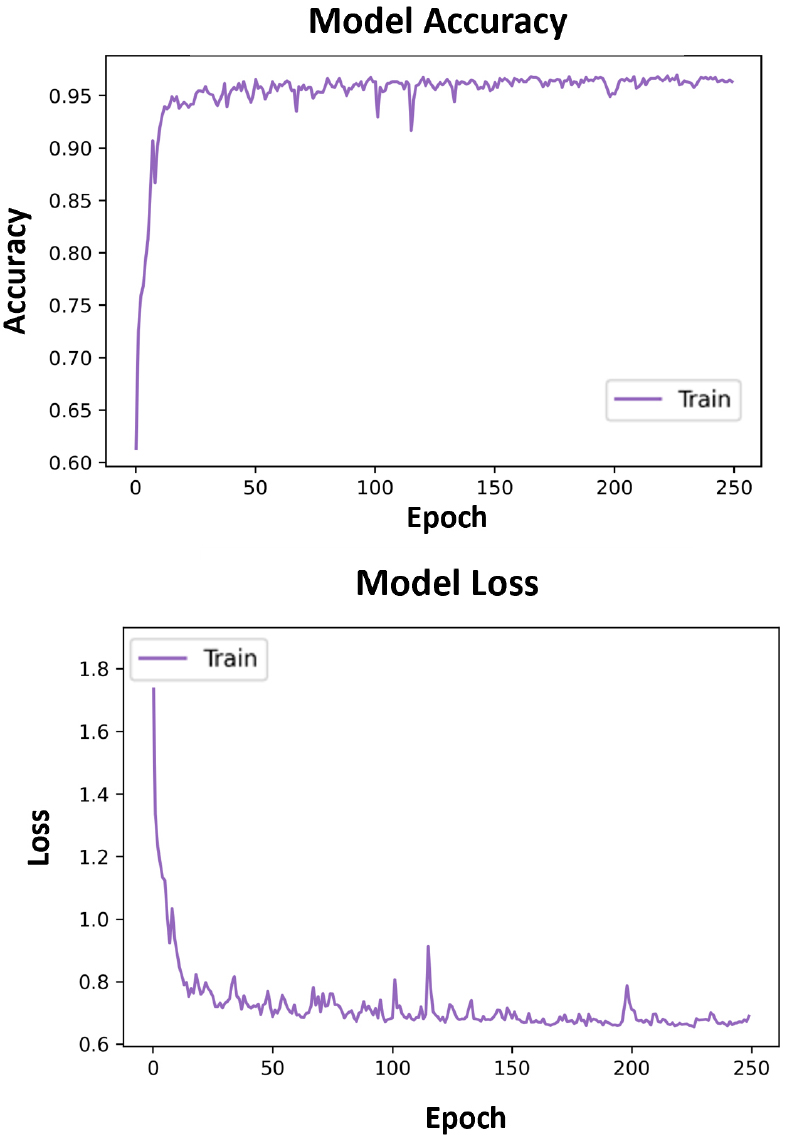
포인트 클라우드 형태의 학습 데이터를 이용하여 데이터 개수에 최적화된 PointNet을 훈련하였으며, Fig. 3은 학습 과정의 정확도(accuracy) 및 오차(loss)의 변화를 시각적으로 보여준다. 전반적으로 학습을 진행할수록 손실값(loss)이 낮아지는 방향으로, 정확도(Accuracy)는 높아지는 경향을 보이는 것으로 보아 모델 파라미터의 개수가 상대적으로 적음에도 불구하고 학습이 잘 진행되었음을 알 수 있다. 여기서 에폭(epoch)은 알고리즘이 전체 데이터에 대해 한 번의 학습을 완료한 것을 의미하며, 이러한 학습이 여러 번 진행됨에 따라 알고리즘은 오차를 줄이는 방향으로 모델 파라미터값을 업데이트하게 된다. 연산속도 또한 GPU를 이용할 경우 한 에폭 당 5초로 매우 빠르게 학습되었다.
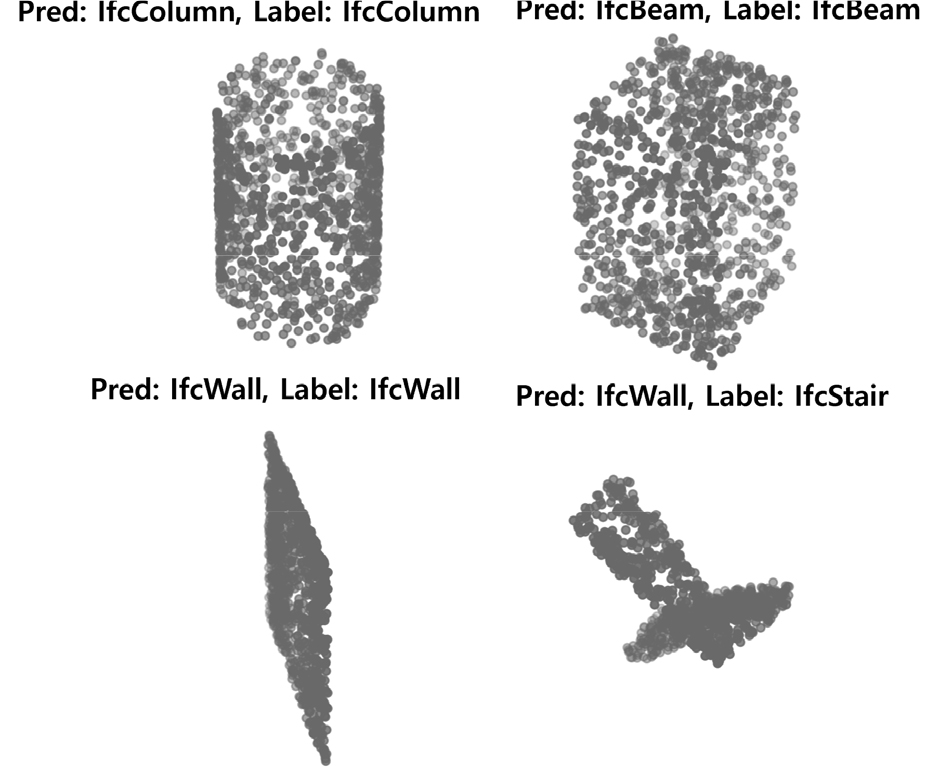
학습이 완료된 분류 모델의 평가를 목적으로 데이터 전처리를 통해 생성된 평가(test) 데이터셋을 활용하여 결과를 먼저 시각적으로 검증하였다(Fig. 4). 예를 들어, Fig. 4에서 IfcColumn의 경우 분류 모델이 IfcColumn으로 예측한 것이 실제로 IfcColumn이었으며, 반면 IfcWall의 경우 모델이 예측한 것이 실제로는 IfcStair였다는 것을 나타낸다. 이러한 과정을 통해 모델의 입력과 출력이 모두 정상적으로 처리되었음을 확인하였다.
5개의 IFC 엔터티에 대해 학습한 분류 모델의 전반적인 학습 정확도(Accuracy)는 0.84로 나타났고, 각 클래스에 속하는 표본 개수로 가중 평균을 낸 Weighted average는 정밀도, 재현율, F1-score가 모두 0.84로 나타났다(Table 3). 이는 앞서 PointNet을 사용하여 BIM 인프라 구조물 부재를 분류한 연구(Koo et al., 2021)의 결과(accuracy: 0.83)와 유사한 수준이라 할 수 있다. 기하학적으로 유사한 Beam과 Column, Slab와 Wall의 F1-socre는 각각 0.96, 0.81, 0.72, 0.86으로 분류 성능이 상대적으로 양호하게 나타났다. 여기서 F1-Score는 정밀도와 재현율의 조화 평균으로 데이터의 편향을 확인하는 지표이며, F1-Score가 1에 가까울수록 분류 성능이 높다고 볼 수 있다. 반면, IfcStair의 경우에는 전혀 분류가 되지 않았는데, 이는 다른 IFC 엔터티에 비해 데이터의 수가 너무 적었기 때문인 것으로 사료된다. 따라서, 본 연구결과는 PointNet과 같은 딥러닝 기법이 3차원 형상 데이터를 분류하는데 대체적으로 양호한 성능을 가지고 있음을 보여주며, 다만, 조금 더 높은 정확도를 확보하기 위해서는 학습에 충분한 양의 데이터 수집이 필수적임을 시사한다. 데이터 개수와 함께 분류 모델의 입력 데이터인 포인트 클라우드의 포인트 개수도 결과에 영향을 미침을 확인하였다. 예를 들어, 1,024개의 포인트를 사용한 결과 0.77의 정확도(accuracy)를 얻었으며, 4,096개를 사용한 결과 0.78의 결과를 얻었다. 이는 포인트의 개수가 구조물의 특징적인 형상을 얼마나 잘 표현하는지와 연관이 있으며, 입력 데이터의 크기 또한 알고리즘의 연산에 영향을 줄 수 있음을 보여준다.
Table 3.
Experiment result
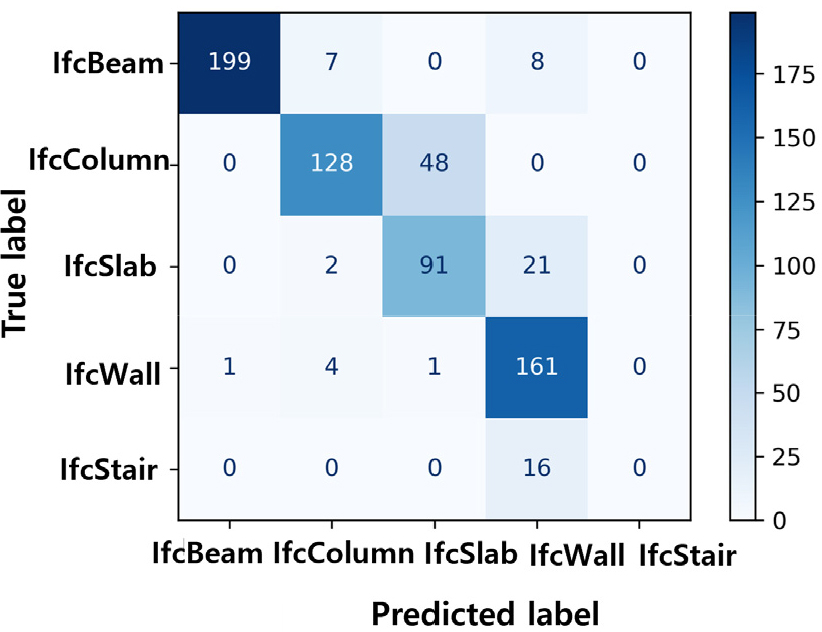
아래 혼돈행렬(Fig. 5)은 분류모델이 각각의 클래스별로 데이터를 얼마나 정확하게 분류했는지를 보여준다. X축은 모델이 예측한 라벨(IFC 엔터티)을 나타내고, Y축은 실제 정답 라벨을 나타낸다. 이를 통해 학습된 분류모델의 성능을 평가할 수 있는 정밀도(Precision)과 재현율(Recall)이 어떤 원인에 의해 산출되었는지를 확인할 수 있다. 정밀도는 모델이 정답인 값이라고 분류한 것 중 실제 정답인 값이고, 재현율은 실제 정답인 것 중 모델이 정답이라고 예측한 비율을 나타낸 것이다. 두 값은 높을수록 성능이 좋은 모델이라고 할 수 있다. 예를 들어, IfcWall의 경우 167의 객체에 대해 분류 모델이 161개를 정확히 예측하였고, 1개를 IfcBeam으로, 4개를 IfcColumn으로, 1개를 IfcSlab로 잘못 분류한 것을 확인할 수 있다. 특히, IfcStair의 경우 16개의 모든 객체가 IfcWall로 오분류되는 결과를 얻었다. 이는 앞서 언급했듯이, 학습한 데이터의 수가 상대적으로 적어 사용된 알고리즘이 전역적인 특징점(Global feature)을 학습하지 못하여 발생한 것으로 판단되며, 비록 형상적으로 차이가 있는 객체라 하더라도 학습 데이터의 수가 학습에 미치는 영향이 클 수 있음을 의미한다.
5. 결 론
본 논문에서는 IFC 기반 시멘틱 강화 자동화를 위한 선행 연구로써 학습 데이터가 딥러닝 알고리즘의 성능에 미치는 영향을 (1) 학습 데이터 구축을 위한 IFC 데이터 전처리, (2) 지도학습 기반의 PointNet을 활용하여 IFC 데이터로부터 추출된 3차원 포인트 클라우드 모델을 객체별로 분류하는 2단계의 과정을 통해 조사하였다. 그 결과 분류 모델의 전반적인 성능은 0.84의 분류 정확도를 달성하였다. 하지만 실험을 통해 데이터의 개수가 현저하게 적은 클래스(e.g., IfcStair)에 대해서는 전혀 학습하지 못 하는 현상을 확인하였다. 이는 전역적인 특징점(Global feature)를 통해 분류를 학습하는 알고리즘 특성상 특정 구조물의 특징을 학습하기 위해서는 충분한 양의 데이터가 필요함을 의미한다. 또한, 입력 데이터의 크기(포인트 클라우드의 포인트 개수)도 분류 모델의 성능에 영향을 미칠 수 있음을 확인하였다. 이러한 연구 결과는 딥러닝 기법의 성공적 활용을 위해서는 알고리즘의 개발과 함께 다량의 양질 데이터셋 구축이 무엇보다 중요함을 시사한다.
최근에는 포인트 클라우드 데이터를 기반으로 한 분류, 객체 탐지, 시멘틱 세그멘테이션에 대한 연구가 활발히 이루어지고 있다. 본 연구에서 활용된 PointNet을 시작으로 포인트 클라우드로부터 유의미한 정보를 추출하는 다양한 딥러닝 알고리즘들이 연구되었다. 이러한 딥러닝 알고리즘은 BIM 분야와 접목되어 구조물의 형상적 패턴을 인식하고 예측하는데 활용될 수 있으리라 판단된다. 향후 이 연구를 통해 얻은 한계점과 개선점을 통해 IFC 기반 시멘틱 강화 자동화에 대한 연구가 지속적으로 발전될 것이라 기대된다.
