

1. 연구배경
2. 기존의 가상 학습 데이터 생성 방법 및 한계점
3. 가상 건설 이미지 자동 생성 프레임워크
3.1 3D 작업자 모델링
3.2 2D 이미지 생성 및 증강
3.3 이미지 데이터 자동 라벨링
4. 실험 및 결과 분석
5. 결 론
1. 연구배경
건설 생산성과 안전성 혁신을 위한 효과적인 수단으로 로봇 자동화 및 디지털화(Robotic Automation and Digitalization)에 대한 사회적 수요와 관심이 증가하고 있다(Kim et al., 2019; Kim and Chi, 2021). 미래 건설현장에서는 로봇시스템이 육체적으로 힘들고 위험한 작업을 수행하는 반면(Kim et al., 2022), 사람은 건설로봇을 제어 ․ 운영하고 갑자기 발생한 사건사고를 관리하는 데 중점을 둘 것이다(Liang et al., 2021). 또한, 건설로봇은 대규모 작업장을 돌아다니면서 현장정보를 수집, 저장, 분석하여 디지털 트윈(Digital Twin)을 실시간 구축할 수 있으며, 이를 통해 건설관리자는 디지털 데이터 기반으로 현장작업을 정확하고 면밀하게 모니터링할 수 있다. 이러한 로봇 자동화 및 디지털화의 이점은 건설산업의 전반적인 생산성과 안전성을 향상할 것으로 기대되고 있다.
로봇 자동화 및 디지털화를 성공적으로 구현하기 위해서는 끊임없이 변화하고 복잡한 건설현장을 시각적으로 이해하는 기능이 필수적이다(Kim et al., 2021). 예를 들어, 건설로봇이 주어진 업무를 수행하기 위해 계획된 작업위치로 이동하려면 작업자, 구조물, 이동통로 등 주변물체와 환경을 시각적으로 인식 ․ 이해하고, 이에 따른 적절한 의사결정을 내려야 한다. 하지만 심층신경망(Deep Neural Network, DNN)이 시각적 장면 이해(Visual Scene Understanding)의 핵심요소가 되면서, 높은 성능의 DNN 모델을 개발하기 위해서는 양질의 학습 이미지 데이터셋을 구축해야 하며 이는 너무 많은 시간과 비용이 요구된다(Hwang et al., 2022; Kim et al., 2020). 이로 인해 기존연구에서 구축한 학습 데이터셋의 크기와 다양성이 제한될 수밖에 없었고, DNN 모델의 잠재력을 최대화하는 데 한계가 있었다.
이러한 한계를 해결하기 위해서 본 연구는 가상의 물리적 환경에서 건설물체와 주변환경을 모델링하고 수많은 인공 이미지를 자동으로 생성 ․ 라벨링할 수 있는 가상 이미지 합성 방법을 제안한다. 현장을 직접 방문하지 않고 사람의 노력 없이 학습용 건설 이미지를 자동으로 생성할 수 있다면 DNN 모델 개발에 획기적일 것이다. 이를 위해 본 연구는 Synthetic Human for Real Tasks(SURREAL)(Varol et al., 2017)를 활용하여 가상의 건설 이미지 데이터셋을 구축하고 DNN 모델 학습 및 테스트 실험을 수행하여, 가상 건설 이미지가 DNN 학습 데이터로써 사용될 수 있는지 그 잠재력을 평가한다. 특히, 본 연구는 실제 건설현장에서 수집된 학습 이미지 데이터의 개수가 적고 그 시각적 다양성이 제한된, 일반적인 실무 시나리오에서 가상 데이터의 잠재력을 조사한다.
2. 기존의 가상 학습 데이터 생성 방법 및 한계점
건설분야에서 학습 이미지 데이터셋의 제한된 크기와 시각적 다양성 문제를 해결하기 위해 가상 이미지 생성과 관련된 여러 연구가 진행되었다. 예를 들어, Soltani et al.(2016)은 3D 가상 굴삭기 모델을 활용하여 건설 학습 이미지를 합성하고 굴삭기를 인식하는 DNN 모델을 학습시키는 데 성공하였다. 이와 유사하게, Assadzadeh et al.(2022)은 3D 굴삭기 모델의 물리적인 움직임을 시뮬레이션하고 굴삭기의 2D 자세추정(Pose Estimation)을 위한 학습 이미지 데이터셋을 구축하였다. 다른 연구에서는 이 방법을 굴삭기의 3D 자세추정(Mahmood et al., 2022)과 작업인식(Activity Recognition)(Torres Calderon et al., 2021)에도 확장 적용하였다. 이러한 가상 이미지 합성 방법은 건물(Braun and Borrmann, 2019), 교량(Hong et al., 2021), 하수관(Siu et al., 2022) 등 다양한 유형의 건설물체에 관해서도 그 잠재력이 확인되었다.
이처럼 많은 연구들이 가상의 건설 이미지를 합성하는 방법을 제안하였으나 다음과 같은 지식격차로 인해 아직까지 DNN 학습 데이터로서의 잠재력을 충분히 활용하지 못하고 있다. 첫째, 실제 건설현장에서 자주 발생하는 시나리오 중 하나인 실제 학습 데이터셋의 크기가 작고 그 시각적 다양성이 제한되었을 때, 가상 이미지의 효과가 불분명하다. 둘째, 가상 이미지 데이터셋의 크기가 DNN 성능에 미치는 영향이 모호하다. 가상 이미지 생성 방법의 가장 큰 장점 중 하나는 학습 데이터를 무한히 만들 수 있다는 것이지만, 기존 연구에서는 DNN 모델 개발에 특정 개수의 가상 이미지만 사용하였다. 마지막으로, 기존연구들은 대부분 건설장비, 건물, 교량, 하수관 등 상대적으로 가상 모델링이 용이한 물체에만 초점을 맞추었기 때문에 인간 작업자에 대한 가상 이미지의 효과가 알려지지 않았다.
위와 같은 지식격차를 해소하기 위해서 본 연구는 실제 건설현장에서 구축된 학습 데이터셋의 크기가 작고 그 시각적 다양성이 편향되었을 때 가상 이미지가 DNN 학습 데이터로 활용될 수 있는지 그 잠재력을 조사한다. 이를 위해 (1) 주요 이미지 합성 방법 중 하나인 SURREAL을 건설 작업자용으로 맞춤 개발하여 가상 건설 이미지 데이터셋을 구축하고, (2) 주어진 작고 편향된 실제 학습 데이터셋을 생성된 가상 이미지와 통합 ․ 개선한 뒤, (3) 통합된 데이터셋으로 DNN 모델을 학습하고 실제 건설현장에서 성능을 평가한다.
3. 가상 건설 이미지 자동 생성 프레임워크
본 프레임워크는 총 3단계로 (1) 3D 작업자 모델링, (2) 2D 이미지 생성 및 증강, (3) 이미지 데이터 자동 라벨링으로 구성되며(Fig. 1), 단계별 세부내용은 다음과 같다.
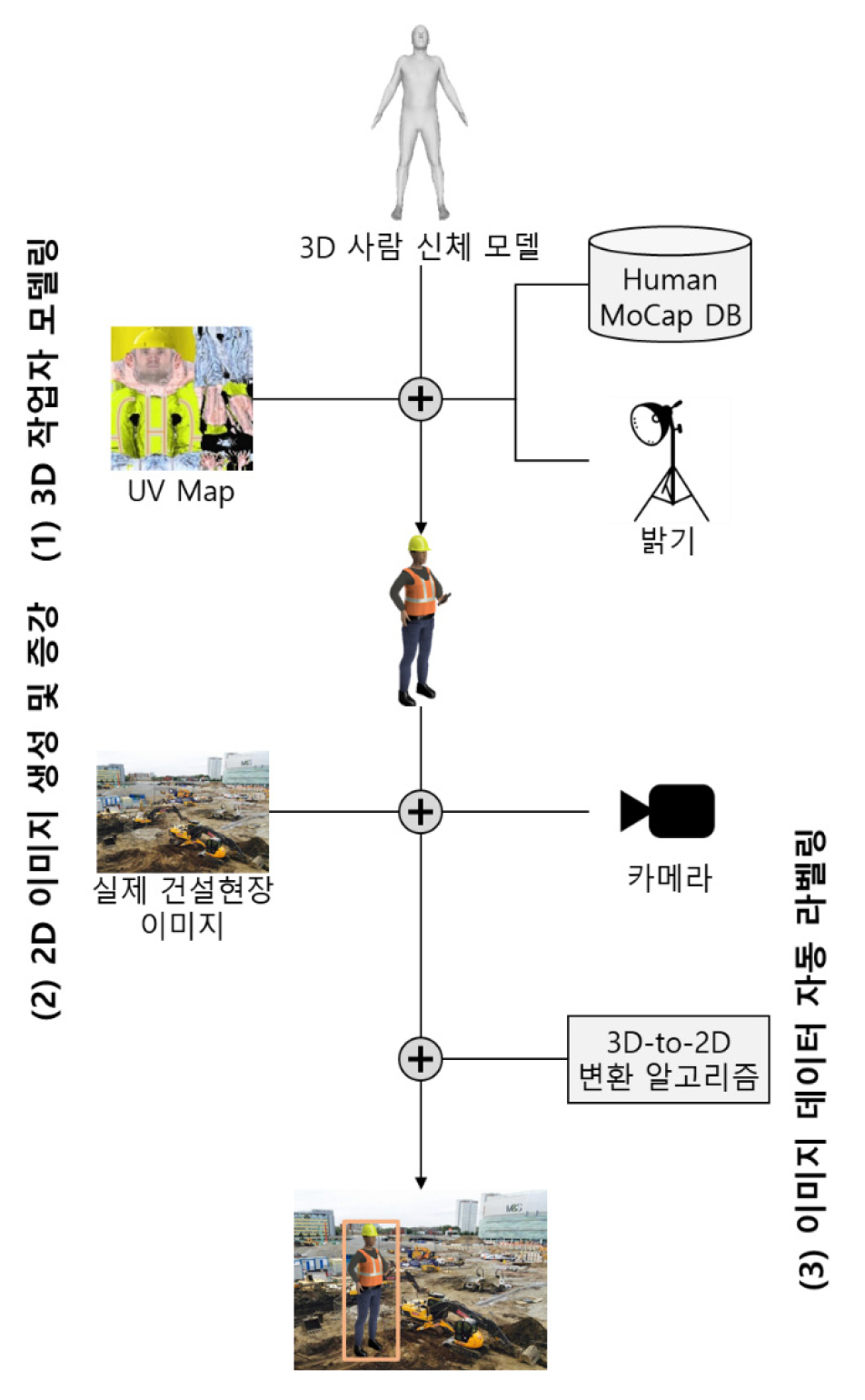
3.1 3D 작업자 모델링
본 단계에서는 가상환경에서 3D 작업자를 모델링하고 물리적 움직임을 시뮬레이션한다. 이를 위해 사람의 신체를 정확하고 자세하게 나타낼 수 있는 Skinned Multi-Person Linear(SMPL) 모델(Loper et al., 2015)을 활용하고, 3D 모델의 질감을 표현하는 UV Map을 건설맞춤형으로 설계하였다. 특히 노란색, 주황색, 하얀색 등 다양한 색상의 안전모와 안전조끼에 대한 UV Map을 개발하였다. 그 다음, Carnegie Mellon University의 Graphics Lab Motion Capture Database를 활용하여 건설 작업자의 다양한 행동을 가상환경에서 시뮬레이션하였다. 해당 데이터베이스에는 총 23개의 사람행동(서기, 걷기, 구부리기 등)에 관한 2,000개 이상의 비디오 데이터가 있어 가상 데이터셋의 크기와 시각적 다양성을 충분히 확보할 수 있었다. 마지막으로, Spherical Harmonics 알고리즘을 이용하여 3D 작업자 모델의 밝기를 조절하였다. 이를 통해 실외 건설현장에서 발생하는 다양한 밝기를 나타낼 수 있었다.
3.2 2D 이미지 생성 및 증강
본 단계의 목표는 앞서 개발한 3D 작업자 모델을 활용하여 2D 가상 이미지를 생성하고 증강하는 것이다. 먼저, Fig. 1과 같이 가상의 3D 작업자 모델을 실제 건설현장에서 수집된 이미지 위에 중첩하여 놓는다. 실제 건설현장 이미지를 배경으로 사용함으로써, DNN 모델이 주변환경(구조물, 중장비 등)과 인식하고자 하는 물체(작업자)를 정확히 구별하고 인식하는 방법을 학습할 수 있었다. 본 연구에서는 웹사이트(구글)에서 수집된 총 529장의 실제 건설현장 이미지를 사용하였다. 그 다음, 잘 구축된 가상환경에 카메라를 임의로 배치하고 2D 작업자 이미지를 생성하였다. 가상환경에서는 어떠한 실무적 제약조건 없이 카메라를 임의의 거리와 각도에 배치할 수 있기 때문에 건설 작업자의 시각적 특성(크기, 촬영각도 등)을 다각화하여 충분한 양과 다양성의 학습 이미지 데이터셋을 구축할 수 있었다. 여기서 카메라 거리는 Gaussian 분포 함수(평균: 30m, 표준편차: 1m)에서 임의로 결정되었으며, 카메라 각도는 0과 값 사이에서 무작위로 샘플링되었다.
3.3 이미지 데이터 자동 라벨링
본 단계는 생성된 2D 이미지에서 가상의 작업자 위치를 자동으로 라벨링한다. 이를 위해 가상환경에서 주어진 카메라의 내부(초점거리, 주점)와 외부 매개변수(회전, 평행이동)를 토대로 3D 좌표를 2D 이미지 좌표로 변환하는 3D-to-2D 변환 알고리즘을 사용하였다. 그 결과, 총 20,386 장의 가상 작업자 이미지를 생성할 수 있었다.
4. 실험 및 결과 분석
가상환경에서 생성된 건설현장 이미지의 잠재력을 평가하기 위해서 본 연구는 DNN 모델 학습 및 테스트 실험을 수행하였다. 특히, 실제 건설현장에서 수집된 학습 이미지 데이터 개수가 적고 그 시각적 다양성이 제한된, 일반적인 실무 시나리오를 가정하였다. DNN 아키텍처는 물체인식 분야에서 가장 자주 대표적인 것 중 하나인 You Only Look Once의 세번째 버전(YOLOv3)으로 선정하였으며, Average Precision(APworker)을 성능 평가 지표로 이용하였다.
본 연구결과를 보다 일반화하기 위해서 다음과 같이 세 가지 시나리오에 대해 실험을 수행하였다: 실제 학습 데이터 샘플(실제 건설현장 이미지에 포함된 작업자의 수)이 500개, 1,000개, 2,000개만 주어진 경우. 세 가지 모든 경우에서 실제 학습 데이터셋은 앞서 구축된 가상 이미지 데이터셋과 통합되었으며, 더 자세한 내용은 아래와 같다.
∙시나리오 #1(실제 작업자에 대한 학습 데이터 샘플이 500개만 주어진 경우): 공개된 벤치마크 데이터셋인 Moving Objects in Construction Sites(MOCS)에서 작업자에 관한 실제 학습 데이터 샘플을 무작위로 500개 선택하였다. 작고 편향된 실제 데이터셋을 개선하기 위해 앞서 구축한 가상 데이터셋에서 1,000개 간격으로 1,000개에서 10,000개까지 가상 작업자 이미지를 무작위 선택하고 이를 학습 데이터 샘플로 추가 사용하였다.
∙시나리오 #2(실제 작업자에 대한 학습 데이터 샘플이 1,000개만 주어진 경우): 실제 작업자에 대한 학습 데이터 샘플이 1,000개인 것을 제외하고 시나리오 #1과 모든 실험조건이 동일하다.
∙시나리오 #3(실제 작업자에 대한 학습 데이터 샘플이 2,000개만 주어진 경우): 실제 작업자에 대한 학습 데이터 샘플이 2,000개인 것을 제외하고 시나리오 #1과 모든 실험조건이 동일하다.
위와 같이 통합 ․ 구축된 세 종류의 학습 데이터셋을 이용하여 DNN 기반 건설 작업자 인식 모델을 각각 학습하였고, MOCS 데이터셋에서 무작위 추출한 10,000개의 학습 데이터 샘플을 이용하여 모델 성능을 평가하였다. 특히 빠르고 안정적인 DNN 모델 학습을 위해 Common Objects in Contexts Dataset을 사전 학습한 가중치로 YOLOv3 아키텍처를 초기화하였다. 또한, Cosine Annealing 학습률 스케줄러 기반(초기값: 1e-4, 최종값: 1e-6)의 Adam 최적화 알고리즘(Batch Size: 8, Epoch: 50)을 사용하였다.
Fig. 2는 세 가지 시나리오에서 가상의 학습 데이터 샘플 수에 따른 모델 성능을 보여준다. 해당 그래프에서 x=0인 실제 학습 이미지만 사용했을 때와 비교하면, 가상 이미지를 추가 사용함으로써 모델 성능을 최소 43.4%에서 최대 59.0% 증가시킬 수 있는 것으로 나타났다. 이 성능 개선은 가상의 학습 데이터가 주어진 실제 이미지 데이터셋의 한정된 양과 시각적 다양성을 효과적으로 보완하고 강화할 수 있음을 나타낸다. 또한, 모든 시나리오에서 2,000개의 가상 학습 데이터 샘플이 추가되었을 때 DNN 모델의 성능이 최대화되었다(Fig. 2). 2,000개의 가상 학습 데이터 샘플을 추가하면 실제 데이터셋의 제한된 양과 시각적 특성을 충분히 보완할 수 있는 것으로 판단된다.
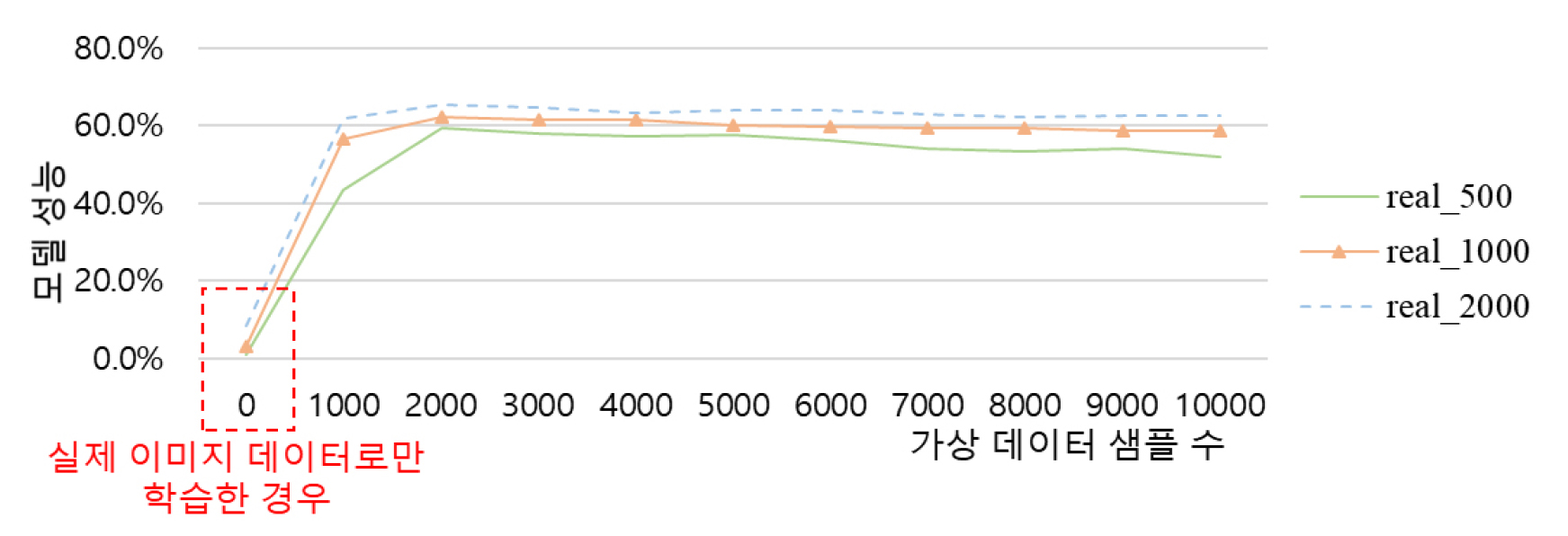
Fig. 3은 총 4,000개의 학습 데이터 샘플(2,000개의 실제 데이터와 2,000개의 가상 데이터)로 학습한 모델이 복잡한 실외 건설현장에서 잘 작동함을 보여준다. 예를 들어, DNN 모델은 다양한 자세를 취하고 있는 다수의 작업자들을 정확히 탐지하였고, 중첩현상이 발생하거나 조명이 어두운 환경에서도 건설 작업자들의 위치를 성공적으로 파악하였다. 또한, 멀리서 촬영된 작은 크기의 작업자들도 잘 인식하는 것을 볼 수 있다. 이처럼 어려운 분석조건에서도 DNN 모델이 잘 작동하는 이유는 개발 프레임워크에서 3D 작업자 모델과 가상환경을 효과적으로 설계했고 2D 이미지를 다양한 위치와 각도에서 촬영했기 때문으로 판단된다. 더불어, 이 결과는 실제 건설현장에서 수집된 학습 이미지 데이터 개수가 적고 그 시각적 다양성이 제한되더라도 잘 구축된 가상환경에서 이미지를 생성 ․ 활용하면 유망한 성능의 DNN 모델을 개발할 수 있다는 것을 시사한다.

실제 데이터 뿐만 아니라 가상 데이터를 함께 사용하는 경우 DNN 모델의 성능이 항상 더 높은 것으로 관찰되었다(Fig. 2). 예를 들어, 500개의 실제 데이터와 2,000개의 가상 데이터로 학습된 모델의 성능은 59.5%였던 반면, 2,000개의 실제 데이터로만 학습된 모델의 성능은 8.3%로 매우 낮았다. 이 결과는 가상 학습 데이터를 동시에 사용하면 실제 데이터의 개수를 2,000개에서 500개로 75%만큼 줄이면서 DNN 모델의 성능을 51.2% 향상할 수 있음을 의미한다. 따라서 주어진 실제 학습 데이터셋의 크기가 작고 시각적 다양성이 편향된 경우, 실제 건설현장 이미지를 추가 수집하고 라벨링하기 보다는 가상 데이터를 활용하는 것이 비용 ․ 성능 측면에서 훨씬 효과적일 것이다.
모든 시나리오에서 2,000개의 가상 데이터 샘플이 추가되었을 때 DNN 성능이 최대화되었으며, 가상 데이터 샘플의 개수가 3,000개 이상으로 넘어가면 성능이 꾸준히 감소하는 것이 관찰되었다(Fig. 2). 특히, (1) 주어진 실제 학습 데이터 샘플의 개수가 적고 (2) 많은 양의 가상 데이터가 추가될수록 DNN 성능 저하가 더 뚜렷하게 발생하였다. 예를 들어, 500개의 실제 데이터와 10,000개의 가상 데이터를 혼합하여 사용할 때 DNN 성능이 최대 성능 대비 7.5%만큼 가장 크게 떨어졌다. 이 성능 저하의 원인은 실제 이미지와 가상 이미지의 시각적 특성이 달라서 발생한 부작용으로 보인다. 만약 서로 다른 특성을 지닌 두 종류의 데이터 소스를 혼합하여 사용하게 되면 DNN 모델 학습이 불안정할 수 있다. 따라서 주어진 작고 편향된 실제 학습 데이터셋을 효과적으로 보완하기 위해서는 적절한 양의 가상 데이터셋을 사용하는 것이 제안된다. 저자의 실험에서는 실제 데이터 대비 2배에서 4배수의 가상 데이터를 사용하는 것이 가장 좋은 결과를 보였다.
5. 결 론
본 연구는 가상환경에서 건설현장 이미지를 자동으로 생성하는 프레임워크를 제안하고 가상 이미지가 DNN 학습 데이터로 사용될 수 있는지 그 잠재력을 평가하였다. 특히, 실제 데이터셋의 크기와 시각적 다양성이 제한된 경우에서 DNN 모델 학습 및 테스트를 수행하였다. 본 실험에서는 실제 데이터와 가상 데이터를 모두 학습한 모델의 성능이 실제 데이터만 학습한 모델의 성능보다 항상 더 높았다(평균 58.1%). 이는 가상 이미지가 작고 편향된 실제 학습 데이터셋의 크기와 시각적 다양성을 충분히 보완하고 강화할 수 있음을 나타낸다. 이러한 기술적 이점으로 인해 실제 데이터와 가상 데이터를 모두 학습한 DNN 모델은 실제 건설현장의 어려운 분석조건(작은 크기의 작업자, 다양한 자세, 어두운 조명, 중첩, 복잡한 배경 등)에서도 작업자를 정확히 인식하고 탐지하였다(Fig. 3). 특히, 가상 학습 이미지 생성 및 라벨링이 완전히 자동화되었다는 점을 고려하면 더욱 고무적인 결과로 생각된다. 뿐만 아니라, 제안된 프레임워크는 다른 유형의 시각적 장면 이해 작업(2D/3D 자세추정, 행동인식, 3D 복원 등)에도 확장 적용될 수 있다. 이를 통해 건설분야에 맞춤화된 다목적 ․ 다용도의 대규모 학습 데이터셋을 구축하고, 실무 적용성을 갖춘 DNN 모델을 개발하는 데 기여할 것이다.
